Приклади кодів символів. Про класах тиску по ANSI і DIN, а також про дюймах і міліметрах
|
Код (двійковий) |
(Десятковий беззнаковий) |
(Десятковий знаковий) |
|
|
А (велика латинська) | |||
|
B (велика латинська) | |||
|
a (мале латинське) | |||
|
А (велике російське) У кодуванні ANSI | |||
|
А (велике російське) У кодуванні ASCII |
Подібний код, як показано вище, відповідає також цілого числа від 0 до 255 в беззнакову (unsigned) форматі. Таким чином, кожному символу відповідає ціле число, також зване кодом символу. Сукупність кодів символів називається кодовою таблицею або кодуванням .
Для персональних комп'ютерів найбільш поширені кодові таблиці ANSI (American National Standard Institute) і ASCII (American Standard Code for Information Interchange). Таблиця ANSI застосовується в Windows, а ASCII застосовувалася в DOS. Однак в цих двох таблицях перші 128 кодів (від 0 до 127) збігаються ; вони розрізняються лише подальшими 128 кодами, використовуваними для зберігання національних (російських) букв і символів "псевдографіки".
У наведених таблицях позначення КС означає "код символу", а З - "символ".
Стандартна частина таблиці символів (ascii-ansi)
Деякі з перерахованих вище символів мають особливий сенс. Так, наприклад, символ з кодом 9 позначає символ горизонтальної табуляції, символ з кодом 10 - символ перекладу рядка, символ з кодом 13 - символ повернення каретки.
Іноді навіть досить досвідчений фахівець не відразу скаже вам, чому відповідає те чи інше значення тиску або довжини в одній системі значень в іншій системі величин.
щоб полегшитивам це завдання, ми пропонуємо таблиці співвідношення величин тиску і довжини в європейській і американській системах з невеликими поясненнями. Але спочатку кілька слів про самих стандартах.
DIN - це німецький стандарт (розшифровується як Deutsches Institut für Normung, Тобто розроблений Німецьким інститутом стандартизації), який розробляється строго в рамках положень Міжнародної організації зі стандартизації - ISO (International Organization for Standardization).
ANSI - стандарт, прийнятий в Сполучених Штатах Америки. розшифровується як American National Standards Institute, Тобто стандарт Американського національного інституту по стандартизації.
Відповідно, норми ANSI визначаються саме цим інститутом, і далеко не завжди між стандартами DIN і ANSI можна простежити точні відповідності в різних сферах.
Переклад одиниць тиску з ANSI в DIN
Тут все просто: якщо за стандартом ANSI навпаки тиску стоїть цифра 150 - це означає, що номінальне (на яку розрахована арматура) тиск становить 20 бар, 300 - 50 бар і т.д. Максимальне значення по ANSI Class - 2500 дорівнюватиме 420 бар за європейським стандартом DIN.
Користуючись цією таблицею, не складно переводити значення тиску і назад: з DIN в ANSI, Хоча здійснювати таке переведення нашим інженерам потрібно набагато рідше.
Переклад одиниць довжини з американської системи в європейську (російську)
Як відомо, американці все вимірюють дюймами і футами, а ми і європейці - міліметрами, сантиметрами і метрами, тобто, як і переважна більшість держав світу, ми живемо в метричної системі одиниць.
Як же переводити дюйми в міліметри? Насправді, в цьому також немає нічого складного, досить лише запам'ятати, що 1 дюйм дорівнює 25,4 мм. Однак нерідко цифрою після коми нехтують і для рівного рахунку вказують, що 1 дюйм = 25 мм.
Таким чином, якщо, наприклад, перетин вхідного отвору дорівнює 2 дюйми по американській системі заходів, то, перевівши за вищевказаною правилом це значення в нашу систему заходів, отримуємо 50 мм або, що більш точно - 51 мм (округливши 50,8 за правилами) .
Залишилося додати, що діаметр в технічних характеристиках маркується латинськими літерами DN і нерідко вказується саме в дюймах, А тиск позначається за допомогою букв PN і вказується найчастіше в барах- у всякому разі, ми використовуємо саме таке маркування як найбільш зручну.
А наступна таблиця допоможе вам вирахувати не тільки точне кількість міліметрів в одному дюймі (з точністю до тисячної міліметра), але і допоможе дізнатися, скільки міліметрів міститься, наприклад, в 2,5 дюймах.
Для цього знаходимо колонку 2 "" (2 дюйма), а зліва шукаємо значення 1/2. Разом 2,5 дюйма = 63,501 мм, що цілком можна округлити до 64 мм, а, наприклад, 6,25 дюйма (тобто 6 і 1/4) = 158,753 мм або 159 мм.
|
| Дюйми "" в міліметрах |
|||||||
|
| ||||||||
|
| ||||||||
Якщо вам потрібно ввести лише кілька спеціальних символів або знаків, ви можете скористатися таблицею символів або поєднаннями клавіш. Список символів ASCII см. В наведених нижче таблицях або в розділі Вставка букв національних алфавітів за допомогою сполучень клавіш.
Примітки:
Вставка символів в кодуванні ASCII
Щоб вставити символ в кодуванні ASCII, натисніть і утримуйте клавішу ALT, А потім наберіть код символу. Наприклад, для вставки знака градуса (º) слід, утримуючи клавішу ALT, набрати на цифровій клавіатурі код 0176.
Примітка:
Вставка символів в кодуванні Юнікод
важливо: деякі програми Microsoft Office, Наприклад PowerPoint і InfoPath, не вдається перетворити Юнікод коди символів. Якщо потрібно знака Юнікод і використовуєте одну з програм, які не підтримують символів Юнікоду, за допомогою для введення знаків, яка може знадобитися.
Примітки:
Закрийте всі відкриті програми.
Двічі клацніть значок Установка і видалення програм на панелі управління.
Виконайте одну з таких дій.
якщо додаток Microsoft Office встановлено як частина Microsoft Office, виберіть Microsoft Office в полі встановлені програми , А потім натисніть кнопку замінити;
Якщо додаток Office було встановлено окремо, клацніть його назву в списку встановлені програми, А потім натисніть кнопку змінити.
Числа слід набирати на цифровій клавіатурі, а не на алфавітно-цифровий. Якщо для введення чисел на цифровій клавіатурі потрібно натиснути клавішу NUM LOCK, переконайтеся, що це зроблено.
Якщо у вас виникають проблеми з перетворенням коду Юникода в символ, наберіть код на цифровій клавіатурі, виділіть його, а потім натисніть клавіші ALT + X.
В Microsoft Windows XP і пізніших версіях універсальний шрифт для Юникода встановлюється автоматично. У Microsoft Windows 2000, шрифт Юникода необхідно встановити вручну.
У Microsoft Windows 2000,
У діалоговому вікні Установка Microsoft Office 2003 виберіть параметр Додати або видалити компоненти, А потім натисніть кнопку далі.
Оберіть Додаткова настройка додатків і натисніть кнопку далі.
розгорніть список Загальні засоби Office.
розгорніть список багатомовна підтримка.
Натисніть піктограму універсальний шрифт і виберіть потрібний параметр установки.
Використання таблиці символів
Таблиця символів - це вбудована в Microsoft Windows програма, Яка дозволяє переглядати символи, доступні в обраному шрифті. За допомогою таблиці символів можна копіювати окремі символи або групи символів у буфер обміну, а потім вставляти їх в програму, яка їх підтримує.
Натисніть кнопку Пуск, А потім виберіть пункт програми, стандартні, службові і Таблиця символів.
Щоб вибрати символ в таблиці символів, клацніть його, натисніть кнопку вибрати, клацніть правою кнопкою миші в тому місці документа, в яке потрібно додати символ, і виберіть команду вставити.
Поширені коди введені за допомогою символів
Додаткові символи символ читайте в статті, встановленої на комп'ютері, коди символів ASCII або діаграми коду знака Юникода сценарієм.
|
знак |
знак |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Символи грошових одиниць |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Юридичні символи |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
математичні символи |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
дробу |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Знаки пунктуації та діалектні символи |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
символи форм |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Поширені коди діакритичних знаківПовний список гліфів та відповідних кодів символів см. в.
|
Фреймворк Bootstrap: швидка адаптивна верстка
Покроковий відеокурс з основ адаптивної верстки в фреймворку Bootstrap.
Навчитеся верстати просто, швидко і якісно, використовуючи потужний і практичний інструмент.
Верстайте на замовлення і отримуйте гроші.
Безкоштовний курс "Сайт на WordPress"
Хочете освоїти CMS WordPress?
Отримайте уроки по дизайну і верстці сайту на WordPress.
Навчіться працювати з темами і нарізати макет.
Безкоштовний відеокурс по малюванню дизайну сайту, його верстці та встановлення на CMS WordPress!
* Наведіть курсор миші для припинення прокрутки.
Назад вперед
Кодування: корисна інформація та коротка ретроспектива
Дану статтю я вирішив написати як невеликий огляд, що стосується питання кодувань.
Ми розберемося, що таке взагалі кодування і трохи торкнемося історії того, як вони з'явилися в принципі.
Ми поговоримо про деякі їх особливості а також розглянемо моменти, що дозволяють нам працювати з кодуваннями більш усвідомлено і уникати появи на сайті так званих кракозябрами, Тобто незрозумілими символами.
Отже, поїхали ...
Що таке кодування?
Спрощено кажучи, кодування - це таблиця зіставлень символів, які ми можемо бачити на екрані, певним числовим кодам.
Тобто кожен символ, який ми вводимо з клавіатури, або бачимо на екрані монітора, закодований певною послідовністю бітів (нулів і одиниць). 8 біт, як ви, напевно, знаєте, рівні 1 байту інформації, але про це трохи пізніше.
Зовнішній вигляд самих символів визначається файлами шрифтів, Які встановлені на вашому комп'ютері. Тому процес виведення на екран тексту можна описати як постійне зіставлення послідовностей нулів і одиниць якимось конкретним символам, які входять до складу шрифту.
Прабатьком всіх сучасних кодувань можна вважати ASCII.
Ця абревіатура розшифровується як American Standard Code for Information Interchange (Американська стандартна кодировочная таблиця для друкованих символів і деяких спеціальних кодів).
це однобайтового кодування, В яку спочатку закладено всього 128 символів: букви латинського алфавіту, арабські цифри і т.д.
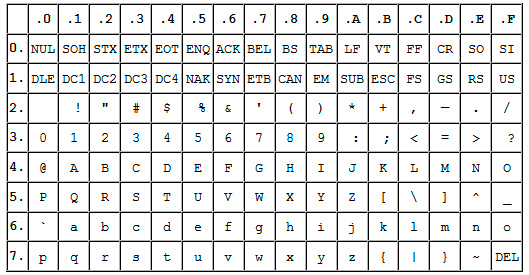
Пізніше вона була розширена (спочатку вона не використовувала всі 8 біт), тому з'явилася можливість використовувати вже не 128, а 256 (2 в 8 ступеня) різних символів, Які можна закодувати в одному байті інформації.
Таке удосконалення дозволило додавати в ASCII символи національних мов, Крім вже існуючої латиниці.
варіантів розширеної кодування ASCII існує дуже багато через те, що мов у світі теж чимало. Думаю, що багато хто з вас чули про таку кодуванні, як KOI8-R - це теж розширена кодування ASCII, Призначена для роботи з символами російської мови.
Наступним кроком у розвитку кодувань можна вважати появу так званих ANSI-кодувань.
По суті це були ті ж розширені версії ASCII, Проте з них були вилучені різні псевдографічні елементи і додані символи типографіки, для яких раніше не вистачало "вільних місць".
Прикладом такої ANSI-кодування є всім відома Windows-1251. Крім типографических символів, в цю систему кодування також були включені букви алфавітів мов, близьких до російського (український, білоруський, сербський, македонський і болгарський).
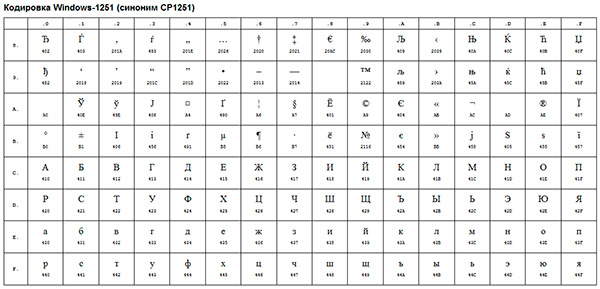
ANSI-кодування - це збірна назва. Насправді, реальна кодування при використанні ANSI буде визначатися тим, що зазначено в реєстрі вашої операційної системи Windows. У випадку з російською мовою це буде Windows-1251, однак, для інших мов це буде інший різновид ANSI.
Як ви розумієте, купа кодувань і відсутність єдиного стандарту до добра не довели, що і стало причиною частих зустрічей з так званими кракозябрами - нечитабельним безглуздим набором символів.
Причина їх появи проста - це спроба відобразити символи, закодовані за допомогою однієї кодувальної таблиці, використовуючи іншу кодіровочние таблицю.
В контексті веб-розробки, ми можемо зіткнутися з кракозябрами, коли, наприклад, російський текст помилково зберігається не в тій кодуванні, яка використовується на сервері.
Зрозуміло, це не єдиний випадок, коли ми можемо отримати нечитаний текст - варіантів тут маса, особливо, якщо врахувати, що є ще база даних, в якій інформація також зберігається в певній кодуванні, є зіставлення з'єднання з базою даних і т.д.
Виникнення всіх цих проблем послужило стимулом для створення чогось нового. Це повинна була бути кодування, яка могла б кодувати будь-яку мову в світі (адже за допомогою однобайтових кодувань при всьому бажанні не можна описати всі символи, скажімо, китайської мови, де їх явно більше, ніж 256), будь-які додаткові спецсимволи і типографіку.
Одним словом, потрібно було створити універсальну кодування, яка вирішила б проблему кракозябрами раз і назавжди.
Юнікод - універсальна кодування тексту (UTF-32, UTF-16 і UTF-8)
Сам стандарт був запропонований в 1991 році некомерційною організацією «Консорціум Юнікоду» (Unicode Consortium, Unicode Inc.), і першим результатом його роботи стало створення кодування UTF-32.
До речі, сама абревіатура UTF розшифровується як Unicode Transformation Format (Формат Перетворення Юнікод).
У цьому кодуванні для кодування одного символу передбачалося використовувати аж 32 біта, Тобто 4 байта інформації. Якщо порівнювати це число з однобайтового кодуваннями, то ми прийдемо до простого висновку: для кодування 1 символу в цій універсальної кодуванні потрібно в 4 рази більше бітів, Що "робить важчою" файл в 4 рази.
Очевидно також, що кількість символів, яке потенційно могло бути описано за допомогою даного кодування, перевищує всі розумні межі і технічно обмежена числом, рівним 2 в 32 ступені. Зрозуміло, що це був явний перебір і марнотратство з точки зору ваги файлів, тому дана кодування не набула поширення.
На зміну їй прийшла нова розробка - UTF-16.
Як очевидно з назви, в цьому кодуванні один символ кодують вже не 32 біта, а тільки 16 (Тобто 2 байта). Очевидно, це робить будь-який символ вдвічі "легше", ніж в UTF-32, однак і вдвічі "важчий" будь-якого символу, закодованого за допомогою однобайтового кодування.
Кількість символів, доступне для кодування в UTF-16 одно, як мінімум, 2 в 16 ступені, тобто 65536 символів. Начебто все непогано, до того ж остаточна величина кодового простору в UTF-16 була розширена до більш, ніж 1 мільйона символів.
Однак і дана кодування до кінця не задовольняла потреби розробників. Скажімо, якщо ви пишете, використовуючи виключно латинські символи, то після переходу з розширеною версією кодування ASCII до UTF-16 вага кожного файлу збільшувався вдвічі.
В результаті, була зроблена ще одна спроба створення чогось універсального, І цим чимось стала всім нам відома кодування UTF-8.
UTF-8 - це багатобайтове кодування зі змінною довгою символу. Дивлячись на назву, можна за аналогією з UTF-32 і UTF-16 подумати, що тут для кодування одного символу використовується 8 біт, проте це не так. Точніше, не зовсім так.
Справа в тому, що UTF-8 забезпечує найкращу сумісність зі старими системами, які використовували 8-бітові символи. Для кодування одного символу в UTF-8 реально використовується від 1 до 4 байт (Гіпотетично можна і до 6 байт).
В UTF-8 все латинські символи кодуються 8 бітами, як і в кодуванні ASCII. Іншими словами, базова частина кодування ASCII (128 символів) перейшла в UTF-8, що дозволяє "витрачати" на їх представлення всього 1 байт, зберігаючи при цьому універсальність кодування, заради якої все і затівалося.
Отже, якщо перші 128 символів кодуються 1 байтом, то всі інші символи кодуються вже 2 байтами і більш. Зокрема, кожен символ кирилиці кодується саме 2 байтами.
Таким чином, ми отримали універсальну кодування, що дозволяє охопити всі можливі символи, які потрібно відобразити, не «обтяжуючи" без необхідності файли.
C BOM або без BOM?
Якщо ви працювали з текстовими редакторами (Редакторами коду), наприклад Notepad ++, phpDesigner, rapid PHP і т.д., то, ймовірно, звертали увагу на те, що при встановленні відповідного кодування, в якій буде створена сторінка, можна вибрати, як правило, 3 варіанти:
ANSI
- UTF-8
- UTF-8 без BOM
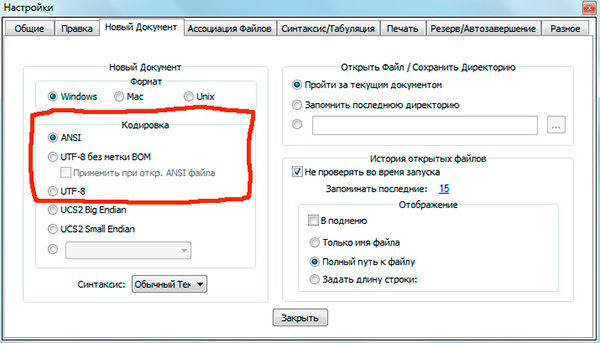
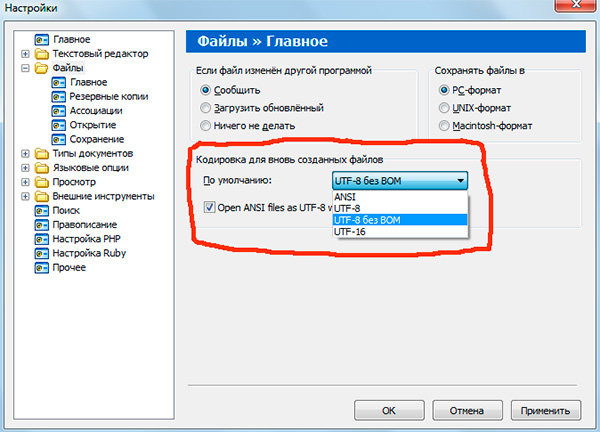
Відразу скажу, що вибирати завжди стоїть саме останній варіант - UTF-8 без BOM.
Отже, що ж таке BOM і чому нам це не потрібно?
BOM розшифровується як Byte Order Mark. Це спеціальний Unicode-символ, який використовується для індикації порядку байтів текстового файлу. За специфікації його використання не є обов'язковим, однак якщо BOM використовується, то він повинен бути встановлений на початку текстового файлу.
Не будемо вдаватися в деталі роботи BOM. Для нас головний висновок такий: використання цього службового символу разом з UTF-8 заважає програмами зчитувати кодування нормальним чином, В результаті чого виникають помилки в роботі скриптів.
Тому, при роботі з UTF-8 використовуйте саме варіант "UTF-8 без BOM". Також краще не використовуйте редактори, в яких в принципі не можна вказати кодування (скажімо, блокнот з стандартних програм в Windows).
Кодування поточного файлу, відкритого в редакторі коду, як правило, вказується в нижній частині вікна.
Зверніть увагу, що запис "ANSI as UTF-8" в редакторі Notepad ++ означає те ж саме, що і "UTF-8 без BOM". Це одне і теж.
![]()
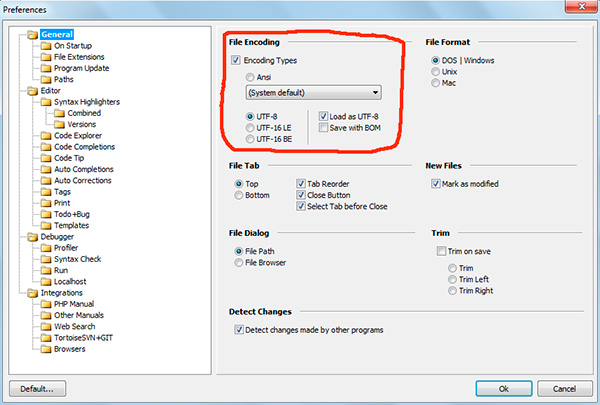
В програмі phpDesigner не можна відразу точно сказати, використовується BOM, чи ні. Для цього потрібно натиснути правою кнопкою миші по напису "UTF-8", Після чого у спливаючому вікні можна побачити, чи використовується BOM (опція Save with BOM).
У редакторі rapid PHP кодування UTF-8 без BOM позначається як "UTF-8 *".
Як ви розумієте, в різних редакторах все виглядає трохи по-різному, проте головну ідею ви зрозуміли.
Після того, як документ збережений в UTF-8 без BOM, Потрібно також переконатися, що вірна кодування вказана в спеціальному метатеге в секції head вашого html-документа:
Дотримання цих простих правил вже дозволить вам уникнути багатьох прогалин з кодуваннями.
На цьому все, сподіваюся, що даний невеличкий екскурс і пояснення допомогли вам краще зрозуміти, що таке кодування, які вони бувають і як працюють.
Якщо вам цікава ця тема з більш прикладний точки зору, то рекомендую вам вивчити мій відеоурок.
Дмитро Науменко.
P.S. Придивіться до преміум-уроків з різних аспектів сайтобудування, а також до безкоштовного курсу по створенню своєї CMS-системи на PHP з нуля. Все це допоможе вам швидше і простіше освоїти різні технології веб-розробки.
Сподобався матеріал і хочете віддячити?
Просто поділіться з друзями і колегами!