Міжнародна кодування ascii. Що таке кодування символів. Автоматичне розпізнавання кодувань
Юнікод підтримує практично всі існуючі набори символів. Найкращою формою кодування набору символів Юнікоду є UTF-8-кодування. У ній реалізована сумісність з ASCII, стійкість до спотворення даних, ефективність і простота обробки. Але про все по порядку.
форми кодування
Комп'ютери оперують числами не просто як абстрактними математичними об'єктами, а як комбінаціями одиниць зберігання і обробки інформації фіксованого розміру - байтів і 32-розрядних слів. Стандарт кодування повинен це враховувати при визначенні способу представлення
Автоматичне розпізнавання кодувань
Що робити, якщо така комбінаційна мітка знаходиться між двома незалежними символами, де вона має схожість, щоб об'єднатися з будь-яким з двох сусідніх незалежних символів? Наприклад, щоб дозволити таку ситуацію, як. Щоб приєднатися до таких незалежним символам, ми можемо зробити наступне. На носії все просто біт і байти.
У Юникоде є 17 площин, а основна площину називається базової багатомовної площиною, а решта 16 називаються додатковими площинами. Ці літаки - це не що інше, як просто категорія для угруповання діапазону кодових точок. Ідея мати такий розподіл в так званих площинах полягає в тому, що кожна площина має особливе значення і містить спеціальні символи.
У комп'ютерних системах цілі числа зберігаються в комірках пам'яті розміром 8 біт (1 байт), 16 або 32 біт. Кожна форма кодування Юнікод визначає, яка послідовність осередків пам'яті представляє ціле число, відповідне конкретному символу. У стандарті представлені три різні форми кодування символів Юнікоду: 8, 16 і 32-бітових блоками. Відповідно, вони звуться UTF-8, UTF-16 і UTF-32. Назва UTF розшифровується як формат перетворення Юнікоду. Кожна з трьох форм кодування є рівноправними засобами представлення символів Юнікоду, має переваги в різних областях застосування.
Можна визначити власні символи і призначити їх кодами в області приватного використання. Але для відображення цих символів необхідно створити новий файл шрифту або оновити існуючий файл шрифту, щоб призначити візуальне уявлення цих символів до відповідними кодами символів. Наприклад, в Японії дуже часто для людей є імена, які не завжди можуть бути написані з використанням існуючих символів, а також потрібні нові символи для їх запису.
Але, оскільки набір символів Юнікоду ріс, це повинно було бути змінено з використанням механізму сурогатної пари для розміщення персонажів з додаткових літаків. Сурогатні пари зазвичай називаються сурогатами і являють собою пари двох кодів Юнікоду з базової багатомовної площині для представлення символів з додатковою площині. У закодованої парі перше значення є високим сурогат, а другий - низький сурогат.
Дані кодування можуть бути використані для подання всіх символів стандарту Юнікод. Таким чином, вони повністю сумісні для рішень, з різних причин використовують різні форми кодування. Кожна кодування може бути однозначно перетворена в будь-яку з двох інших без втрати даних.
принцип ненакладення
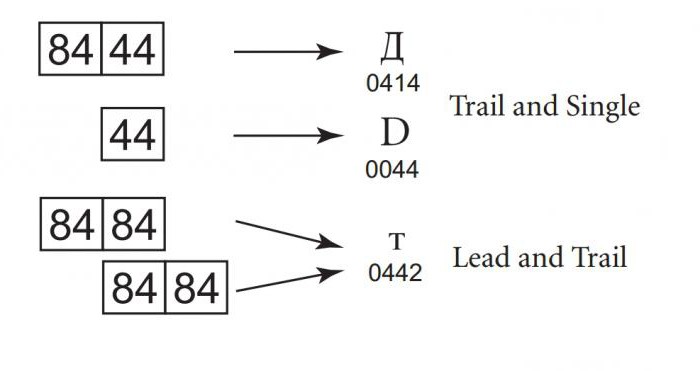
Кожна з форм кодування Юнікоду розроблена з урахуванням неприпустимість часткового накладення. Наприклад, Windows-932 формує символи з одного або двох байтів коду. Довжина послідовності залежить від першого байта, тому значення лідируючого байта в послідовності з двох байтів і одиночного байта не перетинаються. Однак значення одиночного байта і замикає байта послідовності можуть збігатися. Це означає, наприклад, що при пошуку символу D (код 44) можна помилково знайти його входять до другої частини послідовності з двох байтів символу «Д» (код 84 44). Щоб з'ясувати, яка послідовність є правильною, програма повинна врахувати попередні байти.
Значення, що мають одну довжину октету, мають найзначніший біт і найменш значимий біт; тоді як значення, що перевищують одну октетное довжину, мають найзначніший байт і молодший байт. Немає суттєвої переваги одного над іншим: все це залежить від архітектури комп'ютера.
Тому програма має вибирати алгоритм кодування з розумом. Цей підпис на початку потоку даних називається початковою маркою байтового байта. Ті символи, які можуть бути представлені більш ніж одним способом, повинні бути нормалізовані, щоб операції, пов'язані з рядком, працювали правильно. Однак атрибут кодування є необов'язковим.
Ситуація ускладниться, якщо ведучий і замикає байт співпадуть. Це означає, що для зняття неоднозначності буде проводитися зворотний пошук до досягнення початку тексту або однозначної послідовності коду. Це не тільки неефективно, але не захищене від можливих помилок, адже досить одного неправильного байта, щоб весь текст став нечитабельним.
Завжди вказуйте кодування документа, який ви зберігаєте, в діалоговому вікні «Зберегти», і якщо ваш улюблений редактор не дозволяє вам це робити, просто вивантажити його і перейдіть до іншого, що дозволяє вказати кодування файли, які ви зберігаєте.
Мистецтво створення програмного забезпечення, яке може працювати на різних платформах і використовуватися людьми з різних географічних місць, різних культурних традицій і різних мов, називається глобалізацією. У двох словах, це мистецтво створення програмного забезпечення для світової індустрії.
Формат перетворення Юнікоду дозволяє уникнути даної проблеми, тому що значення ведучої, замикає і одиночної одиниці зберігання інформації не збігаються. Завдяки цьому всі кодування Юнікоду підходять для пошуку і порівняння, ніколи не даючи помилкового результату через збіг різних частин коду символів. Той факт, що дані форми кодування дотримуються принцип ненакладення, відрізняє їх від інших мультибайтних східно кодувань.
Мистецтво створення програмного забезпечення, незалежного від базових системних дефолтів, називається інтернаціоналізації. Кожна система має значення за замовчуванням, такі як кодування і локаль. Будь-яка частина програмного забезпечення, яка неусвідомлено покладається на ці значення за замовчуванням, може працювати неправильно при портировании з однієї системи в іншу, оскільки системні значення за замовчуванням варіюються від однієї системи до іншої; і, таким чином, не інтернаціоналізується.
Велику частину часу люди не знають про те, що редактор використовував для збереження свого файлу, або вони просто не дбають. Так само, як ім'я файлу, потрібно завжди знати кодування текстового файлу. Потім він йде вперед і пише програму для читання цього текстового файлу і відображення його вмісту. При написанні програми він не вказує будь-яку кодування для читання цього текстового файлу. Це дуже небезпечно, і така програма дуже легко запалюється. Ніколи, ніколи, не робіть цього, і ми зрозуміємо, чому в той час.
Іншим аспектом неперетинання є те, що кожен символ має чітко визначені межі. При цьому відпадає необхідність в скануванні невизначеного числа попередніх символів. Дану особливість кодувань іноді називають самосинхронізацією. Спотворення однієї одиниці коду введе до спотворення тільки одного символу, а навколишні символи залишаються недоторканими. У 8-бітному форматі перетворення, якщо покажчик посилається на байт, що починається з 10xxxxxx (замість двійкового коду), для пошуку початку символу потрібно від одного до трьох зворотних переходів.
Потім він виконує цю програму на одній машині, і все працює відмінно - як і очікувалося. Він знову запускає ту ж програму в англійській операційній системі. Програма працює, але бум - на цей раз він бачить сміття. Куди пішли ці японські герої? Що ти говориш? - «Не знаю, але на моїй машині відмінно працює!».
Проблема в тому, що при написанні програми програміст покладався на кодування за замовчуванням вихідної операційної системи, Яка виявилася відмінною від кодування за замовчуванням цільової операційної системи. Зверніть увагу, що більше 90% часу за замовчуванням кодування вихідної і цільової систем різна.
узгодженість
Консорціум Юнікоду в повній мірі підтримує всі 3 форми кодувань. Важливо не протиставляти UTF-8 і Юнікод, адже всі формати перетворення - однаково правомірні втілення форм кодування символів стандарту Юнікод.
Байт-орієнтація
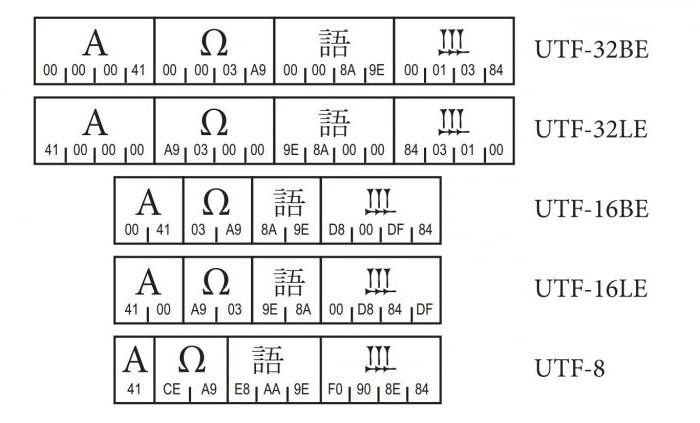
Для подання символу UTF-32 знадобиться одна 32-бітна одиниця коду, яка збігається з кодом Юникода. UTF-16 - від однієї до двох 16-бітних одиниць. А UTF-8 використовує до 4 байт.
Рішення полягає в тому, що програма, в якій програма повинна зчитувати ім'я файлу в якості введення, також повинна завжди запитувати кодування файлу, в якому він був створений, як введення. Але це зовсім інша історія, яку ми розглянемо найближчим часом.
Мистецтво адаптації програмного забезпечення до базового мови називається Локалізацією. Програмне забезпечення повинно покладатися на ці значення за замовчуванням, відображати текстові повідомлення, повідомлення про помилки та інші повідомлення в локалі, на якій він запущений, так що це має сенс для людини, який використовує програмний продукт.
Кодування UTF-8 створена для сумісності з байт-орієнтованими системами на основі ASCII. Велика частина існуючого програмного забезпечення та практика інформаційних технологій тривалий час спиралися на уявлення символів у вигляді послідовності байтів. Безліч протоколів залежить від незмінності і використовує або уникає спеціальні керуючі символи. простим способом адаптувати Юнікод до таких ситуацій можна, застосувавши 8-бітове кодування для представлення символів Юнікоду, еквівалентних будь-якого символу ASCII або керуючому символу. Для цього і призначена кодування UTF-8.
Мовний мова являє собою мову. Отже, адаптація до мови означає, що програмне забезпечення повинно мати можливість відображати або вводити введення в залежності від мови. Наприклад, французька мова є мовою. Але французький, як кажуть у Франції, відрізняється від французького, як кажуть в Канаді. Отже, ми доповнюємо наше визначення мови, щоб сказати, що мовний стандарт являє собою конкретну мову конкретної країни. Знову ж таки, мова, якою розмовляють в певній країні, може мати зміни.
Наприклад, стародавні традиційні китайці говорили в Китаї проти спрощеного китайської мови, говорить в Китаї. Отже, ми знову додамо наше визначення мови, щоб сказати, що мовний стандарт являє собою конкретну мову конкретної країни з варіантами.
Мінлива довжина
UTF-8 - кодування змінної довжини, що складається з 8-бітних одиниць зберігання інформації, старші біти яких позначають, до якої частини послідовності належить кожен окремий байт. Один діапазон значень відведений для першого елемента послідовності коду, інший - для наступних. Це забезпечує не перетинання кодування.
Коли ми пишемо програмне забезпечення, яке адаптується до базового мови, це насправді означає звернення до товариства, яке буде використовувати це програмне забезпечення. Тому такі специфічні для локалі речі, як текстові повідомлення, повідомлення про винятки, дата і час, валюта та інші повідомлення повинні відображатися таким чином, щоб користувач програмного забезпечення розумів, що відображається. Існує спільнота користувачів, до яких намагається звернутися локалізація, тому що ми не хочемо переписувати все програмне забезпечення для кожної мови і будь-який смак цієї мови.
ASCII
UTF-8-кодування повністю підтримує коди ASCII (0x00-0x7F). Це означає, що символи Юнікоду U + 0000-U + 007F конвертуються в єдиний байт 0x00-0x7F UTF-8 і таким чином стають не відрізнятись від ASCII. Більш того, щоб уникнути багатозначності, значення 0x00-0x7F не використовуються більше ні в одному байті представлення символів Юнікоду. Для кодування неідеографіческіх символів, відмінних від ASCII, використовується послідовність з двох байтів. Символи діапазону U + 0800-U + FFFF представлені трьома байтами, а додаткові з кодами більше U + FFFF вимагають чотирьох байтів.
Це передбачає запис програми один раз таким чином, що кожен раз, коли вона виконується, вона використовує стандартну локаль системи, в якій вона виконується, для відображення інформації, яка залежить від локалі. Переклад призначений для перекладу будь-яких текстових повідомлень, повідомлень про помилки та інших повідомлень, які будуть відображатися користувачеві з мови, на якому він написаний, на різні мови, які хоче підтримувати програмне забезпечення.
Наприклад, коли програмне забезпечення написано англійською мовою, все такі текстові повідомлення, які будуть відображатися для користувача, спочатку ідентифікуються і виділяються з коду в іншому файлі. Кожному з цих повідомлень присвоюється унікальний ключ, який програмне забезпечення буде використовувати для відображення повідомлення, ідентифікованого цим ключем. Потім всі ці повідомлення вручну перекладається експертами з мови на різних мовах, які програмне забезпечення хоче підтримати.
Область застосування
Кодуванні UTF-8 зазвичай віддається перевага в протоколі HTML і йому подібним.
XML став першим стандартом з повною підтримкою кодування UTF-8. Організації, що займаються стандартизацією, теж її рекомендують. Проблема підтримки в адресах URL, відмінних від ASCII-символів, була вирішена, коли консорціум W3С і інженерна група IETF дійшли згоди про кодування всіх виключно в UTF-8.
Дивитися що таке "Кодування символів" в інших словниках
Поділ таких текстових повідомлень з коду спрощує управління і переклад повідомлень. Це також допомагає мовним експертам переводити ці файли на інші мови незалежно від програмного коду. Зверніть увагу, що пропозиції не можуть бути переведені з однієї мови на іншу автоматично. Це пов'язано з тим, що пропозиції пов'язані з граматикою. Навіть якщо ми спробуємо автоматизувати це, перекладені пропозиції можуть бути не граматично правильними, а часом можуть не мати ніякого сенсу.
Сумісність з ASCII полегшує перехід до нового програмному забезпеченню. З UTF-8 працює більшість текстових редакторів, в тому числі JEdit, Emacs, BBEdit, Eclipse і "Блокнот" операційної системи Windows. Жодна інша форма кодування Юнікоду не може похвалитися такою підтримкою з боку інструментальних засобів.
Перевага кодування полягає в тому, що вона складається з послідовності байтів. З рядками UTF-8 легко працювати в C та іншими мовами програмування. Це єдина форма кодування, що не вимагає мітки порядку байтів BOM або оголошення кодування в XML.
Тому хтось повинен сісти і перевести всі ці різні повідомлення в різні локалі. Ну, по-перше, чому є третій спосіб? Це зробило б життя набагато простіше, але зараз нічого не поробиш. У будь-якому випадку, це теж непогано, або чи не так? Без кодування це перетворення неможливо взагалі. Вплив величезна - код не переносимо, що означає, що ви можете отримувати різні і неправильні результати, коли така програма виконується на різних машинах, тому що кодування за замовчуванням буде відрізнятися від однієї машини до іншої.
Пам'ятайте, що після завершення перетворення інформація про кодування, пов'язана з байтами або символами, відсутня. Байти - це байти, а символи - символи. Якщо ви хочете конвертувати, ви повинні вказати третю частину інформації - кодування.

самосинхронізація
В оточенні, що використовує 8-бітну обробку символів, в порівнянні з іншими багатобайтові кодуваннями, UTF-8 має наступні переваги:
- Перший байт послідовності коду містить інформацію про його довжині. Це підвищує ефективність прямого пошуку.
- Спрощено процедуру знаходження початку символу, так як початковий байт обмежений фіксованим діапазоном значень.
- Відсутня перетин значень байтів.
порівняння переваг
UTF-8-кодування компактна. Але при застосуванні для кодування східно символів (китайських, японських, корейських, що використовують знаки китайського письма) використовуються 3-байтниє послідовності. Також UTF-8-кодування поступається іншим формам кодування по швидкості обробки. А двоичная сортування рядків дає той же результат, що і двоичная сортування Юникода.
Наприклад, файл зберігається у вигляді послідовності біт в файлової системи. Це тягар додатки для обробки необроблених байтів будь-яким способом. Потоки символів - це потоки байтів і кодування. Потік символів не може функціонувати без кодування. Ця кодова точка, яка представляє символ в Юникоде, потім повертається в додаток.
З символів ми не завжди можемо сказати, що таке точна послідовність байтів у вхідному потоці. Так, з огляду на кодування, ми можемо перетворити символи назад в байти, але ця послідовність байтів може бути не завжди такий же, як вихідна послідовність байтів.
Схема кодування символів
Схема кодування символів складається з форми кодування символів і способу побайтного розташування одиниць коду. Для визначення схеми кодування стандартом Юникода передбачено використання початкової мітки порядку байтів (BOM, Byte order mark).
При включенні BOM в UTF-8 функція мітки обмежується тільки зазначенням на використання форми кодування. Проблеми визначення порядку байтів у UTF-8 немає, так як її розмір одиниці кодування дорівнює одному байту. Використання BOM для даної форми кодування не є ні обов'язковим, ні рекомендованим. BOM може зустрічатися в текстах, конвертованих з інших кодувань, що використовують мітку порядку байтів, або для сигнатури кодування UTF-8. Являє собою послідовність з 3 байтів EF 16 BB 16 BF 16.
Це означає, що якщо ви перемістіть програму на іншу машину з іншого кодуванням, ця програма може взагалі не працювати. Замість цього слід завжди використовувати. Нижче наведені два варіанти невеликої програми для читання файлу з використанням відповідної кодування, а потім для його записи з використанням будь-якої зазначеної користувачем кодування.
Вищезазначена програма не повинна нічого робити, крім як правильно створювати читачів і письменників. Вищезазначена програма явно виконує перетворення з використанням кодування перед записом байтів у вихідний файл. Щоб виконати локально-чутливу операцію, спочатку необхідно створити об'єкт локалі. Але завжди можна було явно створити локаль, вказавши або код мови, або код мови, і код країни. Лістинг 3: зумовлений формат дати.
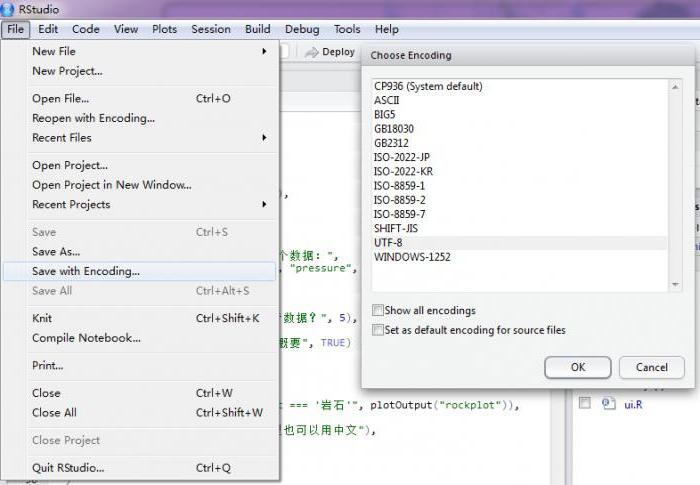
Як задати кодування UTF-8
В UTF-8 встановлюється за допомогою наступного коду:
˂meta http-equiv = "Content-Type" content = "text / html; charset = utf-8" ˃
У PHP кодування UTF-8 задається за допомогою функції header () на самому початку файлу після завдання значення рівня виведення помилок:
error_reporting (-1);
Charset = utf-8 ");
Для підключення до баз даних MySQL кодування UTF-8 встановлюється так:
mysql_set_charset ( "utf8");
В CSS-файлах кодування символів UTF-8 вказується так:
@charset "utf-8";
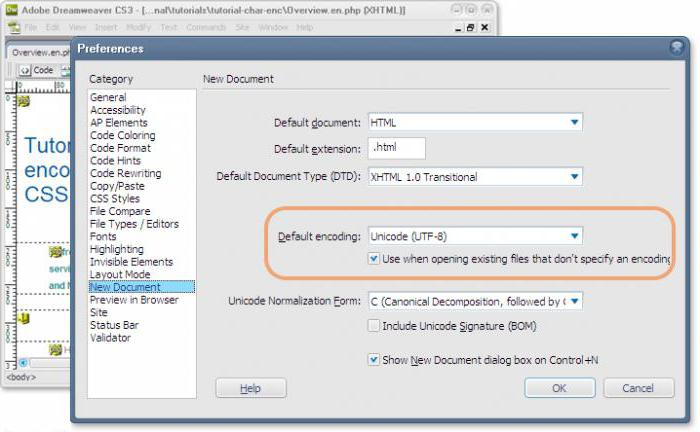
При збереженні файлів всіх типів вибирається кодування UTF-8 без BOM, інакше сайт працювати не буде. Для цього в програмі DreamWeave потрібно вибрати пункт меню «Модифікації - Властивості сторінки - Тема / Кодування», змінити кодування на UTF-8. Потім слід перезавантажити сторінку, прибрати галочку з пункту «Підключити Юнікод сигнатури (BOM)» і застосувати зміни. Якщо який-небудь текст на сторінці або в базі даних був введений іншою формою кодування, то його потрібно ввести нові або перекодувати. При роботі з регулярними виразами обов'язково використовувати модифікатор u.
В текстовому редакторі Notepad ++, якщо кодування відмінна від UTF-8, через пункт меню «Перетворити в UTF-8 без BOM» змінити кодування і зберегти в кодуванні UTF-8.
альтернативи немає
В умовах глобалізації, коли політичні і мовні кордони стираються, набори символів, які мають місцеві особливості, стають малопридатними. Юнікод є єдиним набором символів з підтримкою всіх локалізацій. А UTF-8 - приклад правильної реалізації Юникода, яка:
- підтримує широкий діапазон інструментальних засобів, в тому числі сумісність з кодуванням ASCII;
- має стійкість до спотворення даних;
- проста і ефективна при обробці;
- не залежить від платформи.
З появою UTF-8 дискусії про те, яка форма кодування або набір символів краще, стали безглузді.
Така таблиця зіставляє кожному символу послідовність довжиною в один або кілька байтів.
Хоча термін «набір символів» (англ. character set, charset), Узаконений RFC 2278, зараз є, мабуть, найбільш авторитетним, що передував йому термін «кодування» (англ. encoding) Як і раніше використовується як синонім, зокрема, в мовах програмування,, і.
Нерідко також замість терміна «набір символів» неправильно вживають термін «кодова сторінка», що означає насправді окремий випадок набору символів з однобайтном кодуванням.
В даний час в основному використовуються кодування трьох типів: сумісні з EBCDIC і засновані на Юникоде 16-бітові, з переважною перевагою перших. Подання Юникода сумісно з ASCII. Кодування на базі ДКОИ-8) використовуються тільки на деяких мейнфреймах. Спочатку в кожній операційній системі використовувався один набір символів. Тепер використовувані набори символів, залежать від типу операційної системи лише за традицією і встановлюються відповідно до локалі.
Автоматичне розпізнавання кодувань
Використання безлічі кодувань в сучасному ПО створює багато незручностей не тільки програмістам, але і користувачам. Відповідно до однієї точки зору, впоратися з крокозябра можна, якщо програми будуть автоматично розпізнавати кодування вхідного тексту.
Для однобайтовим кодувань можна враховувати той факт, що частота використання різних букв сильно різниться (наприклад, в російській часто використовується «о», але рідко "ь"). Тому, знаючи мову тексту, можна легко вибрати кодування, в якій частота байтів краще відповідає частоті букв даного мови.
Альтернативна точка зору вважає подібні евристичні алгоритми визначення кодування тексту шкідливими, оскільки сучасні інформаційні технології мають у своєму розпорядженні засобами недвозначно зіставити тексту належну йому кодову сторінку (Див., Наприклад, програм створення текстових даних, що порушують стандарти.
поширені кодування
Дивитися що таке "Кодування символів" в інших словниках:
Кодування російської мови в комп'ютерних програмах і в Інтернеті - - Всі символи, які можуть відображатися на екрані комп'ютера, описані в таблиці символів. У самій першій таблиці символів не було російських букв. Для того роботи з російськими буквами їх треба було вписати в цю таблицю символів замість непотрібних ... ... Енциклопедичний словник ЗМІ
Набір символів (англ. Character set) певна таблиця кодування кінцевого безлічі знаків. Така таблиця зіставляє кожному символу послідовність довжиною в один або кілька байтів. Хоча термін «набір символів» (англ. Character set, ... ... Вікіпедія
Перевірити інформацію. Необхідно перевірити точність фактів і достовірність відомостей, викладених у цій статті. На сторінці обговорення повинні бути пояснення. «Альтернативна кодування» підстав ... Вікіпедія
- (англ. Character set) таблиця, що задає кодування кінцевого безлічі символів алфавіту (зазвичай елементів тексту: літер, цифр, розділових знаків). Така таблиця зіставляє кожному символу послідовність довжиною в один або кілька ... ... Вікіпедія
Юнікод, або Унікод (англ. Unicode) стандарт кодування символів, що дозволяє представити знаки практично всіх письмових мов. Стандарт запропонований в 1991 році некомерційною організацією «Консорціум Юнікоду» (англ. Unicode Consortium, ... ... Вікіпедія
Шестібітние кодування застосовувалися в комп'ютерах, які проводилися в США в 1950 х 1960 х роках. Відповідно розмір машинного слова на цих комп'ютерах був кратний 6 біт (наприклад, 12, 18, 24, 36, 48, 60 біт). Такий розмір символу дозволяв ... ... Вікіпедія