Character encoding windows 1251
Data carriers
Data is a dialectic component of information. They are registered signals. At the same time, the physical registration method can be any: mechanical movement of physical bodies, change of their shape or parameters of surface quality, change of electrical, magnetic, optical characteristics, chemical composition and (or) nature of chemical bonds, change of state electronic system and much more.
Specify the source encoding so that the conversion can be performed to the destination. The following table shows the available identifiers. code page. Question 2. "Wouldn't it be easier to leave?" And since this is not a default, how many hosting companies have taken the trouble to change the default standard to the Brazilian standard? How many programmers, when they could, bother to set up their databases in this way?
Opposite position when we assume part of the environment
In general, we position ourselves as “victims” of our environment: the environment as a fact, and as something driven by decisions, of which we are not a part. If we decide to conform to this “little change,” the questions we have to ask ourselves are completely changed. This answer is partially a reminder of which templates are useful and necessary, especially in Brazil, we spend a lot of time in our lives doing conversions, correcting data, adjusting settings and adapting libraries.
In accordance with the registration method, data can be stored and transported on different types of media. The most common data carrier, although not the most economical, seems to be paper. On paper, data is recorded by changing the optical characteristics of its surface. Changes in the optical properties (changes in the surface reflection coefficient in a certain range of wavelengths) are also used in devices that record by a laser beam on plastic carriers with a reflective coating ( CD-ROM). Magnetic tapes and disks can be mentioned as carriers using a change in magnetic properties. Data logging by changing the chemical composition of the surface media substances is widely used in photography. At the biochemical level, the accumulation and transmission of data in wildlife occurs.
When it comes to computing, computing and digital media, even Portugal means “a colonized country”. Foreign conditions have always been imposed on Portuguese speakers. Gradually, European standards and minimum requirements for expressing the Portuguese alphabet were adopted in a standard way, which are accepted by manufacturers of machines, software and other resources.
Obviously, this is also a “headache” for Brazilian analysts and programmers, in installations, configurations, and especially in data exchange. On the issue of "freedom of choice." There is no need for “one language for all”, since there are no corresponding problems of coordination. The existence of a number of large communities is enough to reduce excess diversity. We have no right to choose the number of our house, it must conform to the model, which is the frame of the street or its yard. If we invent numerology or taste, we create confusion on the street, and we make it difficult to deliver letters at home. In this case, the overall advantage of “adopting a standard” exceeds the personal benefit of diversity.
- They are all "standard languages."
- It is a matter of taste, context, etc. and the programmer "accepts his standard."
- The one-to-one benefits do not outweigh the benefits of diversity.
Data carriers are of no interest to us in themselves, but to the extent that the properties of information are very closely related to the properties of its carriers. Any medium can be characterized by the parameter resolution (the amount of data recorded in the unit of measurement adopted for the carrier) and dynamic range (logarithmic ratio of the amplitudes of the amplitudes of the maximum and minimum recorded signals). Such properties of information as completeness, availability and reliability often depend on these properties of the carrier. So, for example, we can count on the fact that in a database placed on a compact disc, it is easier to ensure the completeness of information than in a similarly designed database placed on a floppy disk, since in the first case the density of data recording is per unit length tracks are much higher. For the average consumer, the availability of information in the book is noticeably higher than the same information on the CD, since not all consumers have the necessary equipment. And finally, it is known that the visual effect of viewing a slide in a projector is much more than from viewing a similar illustration printed on paper, since the range of brightness signals in transmitted light is two to three orders of magnitude greater than that in reflected light.
The task of data conversion to change the carrier is one of the most important tasks of computer science. In the structure of the cost of computing systems, devices for data input and output, working with storage media, make up up to half the cost of hardware.
^ Data operations
During the information process, data is transformed from one type to another using methods. Data processing involves many different operations. With the development of scientific and technological progress and the general complication of relations in human society, labor costs for data processing are steadily increasing. First of all, it is connected with the constant complication of the conditions of production management and society. The second factor, which also causes a general increase in the volume of data processed, is also associated with scientific and technological progress, namely, with the rapid emergence and introduction of new data carriers, storage media and data delivery.
In the structure of possible operations with data one can single out the following main ones:
data collection - the accumulation of data to ensure sufficient completeness of information for decision-making;
data formalization - reduction of data from different sources to the same form in order to make them comparable with each other, that is, to increase their level of accessibility;
data filtering - screening out “extra” data that is not necessary for making decisions; at the same time, the “noise” level should decrease, and the accuracy and adequacy of the data should increase;
data sorting - ordering data by a given attribute for ease of use; increases the availability of information;
data grouping - combining data on a given basis in order to improve ease of use; increases the availability of information;
data archiving - organization of data storage in a convenient and easily accessible form; serves to reduce the economic cost of storing data and increases the overall reliability of the information process as a whole;
data protection - a set of measures aimed at preventing the loss, reproduction and modification of data;
data transport - receiving and transmitting (delivering and delivering) data between remote participants in the information process; the source of data in computer science is called server and the consumer - customer;
data conversion - transfer data from one form to another or from one structure to another. Data conversion is often associated with a change in the type of media, for example, books can be stored in a regular paper form, but for this purpose both electronic form and microfilm can be used. The need for multiple data conversion also arises during their transportation, especially if it is carried out by means not intended for transporting this type of data. As an example, it can be mentioned that for transporting digital data streams over telephone network channels (which were originally focused only on the transmission of analog signals in a narrow frequency range), it is necessary to convert digital data into some sort of sound signals, which is what special devices do. telephone modems.
^ Binary code data encoding
To automate work with data of various types, it is very important to unify their presentation form - for this purpose, the technique is usually used. coding, that is, the expression of data of one type through the data of another type. Natural human languages - it is nothing more than a coding system for expressing thoughts through speech. Close to the languages alphabet (coding system components of the language using graphic symbols). History knows interesting, albeit unsuccessful attempts to create "universal" languages and alphabets. Apparently, the failure to implement them is connected with the fact that national and social entities naturally understand that a change in the coding system of public data necessarily leads to a change in social practices (that is, norms of law and morality), and this may be due to social upheavals. .
The same problem of universal means of coding is quite successfully implemented in certain branches of technology, science and culture. Examples include the math expression system, the telegraph alphabet, the nautical flag alphabet, the Braille system for the blind, and much more.
Fig. 1.8. Examples of different coding systems
Its system exists in computing - it is called binary coding and is based on the presentation of data by a sequence of two characters only: 0 and 1. These signs are called binary numbers in English - binary digit, or abbreviated bit
One bit can be expressed by two concepts: 0 or 1 (Yesor no, black or white truthor Lyingetc.). If the number of bits is increased to two, then four different concepts can already be expressed:
Three bits can encode eight different values:
000 001 010 01l 100 101 110 111
Increasing by one the number of bits in the binary coding system, we double the number of values that can be expressed in this system.
^ Encoding of integers and real numbers
To encode integers from 0 to 255, it is enough to have 8 bits of a binary code (8 bits).
0000 0000 = 0
…………………
1111 1110 = 254
1111 1111 = 255
Sixteen bits allow you to encode integers from 0 to 65535, and 24 bits - more than 16.5 million different values.
For coding real numbers, 80-bit coding is used. The number is pre-converted to normalized form:
3,1415926 = 0,31415926 10 1
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 9
The first part of the number is called mantissa, and the second is characteristic. Most of the 80 bits are allocated for storing the mantissa (along with the sign) and a fixed number of digits is allocated for storing the characteristics (also with the sign).
^ Text Encoding
If each symbol of the alphabet is associated with a specific integer (for example, a sequence number), then using a binary code you can also encode text information. Eight binary bits are enough to encode 256 different characters. This is enough to express all the characters of the English and Russian alphabets, both lowercase and uppercase, as well as punctuation marks, symbols of basic arithmetic operations and some common special symbols, for example the symbol "§".
Technically, it looks very simple, but there have always been quite weighty organizational difficulties. In the early years of the development of computer technology, they were associated with the absence of the necessary standards, and now they are caused, on the contrary, by an abundance of simultaneously operating and contradictory standards. In order for the whole world to encode text data in the same way, uniform coding tables are needed, but this is still impossible because of the contradictions between the characters of national alphabets, as well as corporate contradictions.
For the English language, which has captured the de facto niche of international communication, the contradictions have already been removed. US Institute of Standardization (ANSI - American National Standard Institute) put into operation a coding system ASCII (American Standard Code for Information Interchange - standard code US information exchange). In system ASCII two coding tables are fixed: basic and extended. The base table fixes the values of codes from 0 to 127, and the extended table refers to characters with numbers from 128 to 255.
The first 32 codes of the base table, starting with zero, are given to hardware manufacturers (primarily, manufacturers of computers and printing devices). In this area are located the so-called control codesto which no symbols of languages correspond, and, accordingly, these codes are not displayed either on the screen or on printing devices, but they can control how other data is output.
Starting from code 32 to code 127, the codes of the characters of the English alphabet, punctuation marks, numbers, arithmetic operations and some auxiliary characters are placed. Base coding table ASCII given in table 1.1.
^ Table 1.1. Base table aSCII encoding

Similar text data coding systems have been developed in other countries. For example, in the USSR, the coding system KOI-7 operated in this area. (seven-digit information exchange code). However, the support of manufacturers of equipment and software brought the American code ASCII to level international standard, and national coding systems had to “retreat” to the second, expanded part of the coding system, defining the values of codes from 128 to 255. The absence of a unified standard in this area led to a multiplicity of simultaneously valid encodings. Only in Russia you can specify the three existing coding standards and two more obsolete.
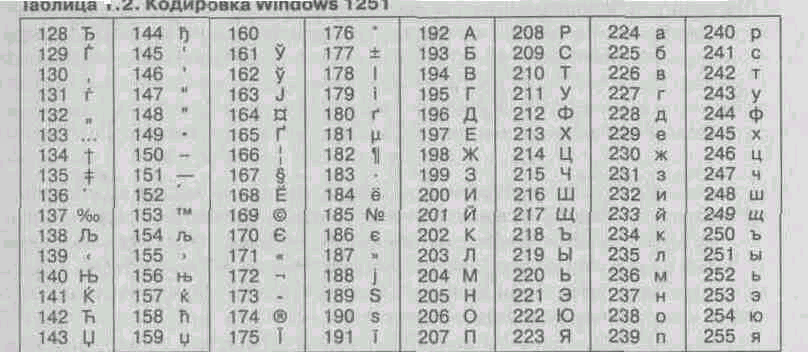
For example, the character encoding of the Russian language, known as the encoding Windows-1251, was introduced “from the outside” by Microsoft, but given the wide distribution of operating systems and other products of this company in Russia, it was deeply entrenched and found wide distribution (Table 1.2). This encoding is used on most local computers running on the Windows platform. In fact, it has become standard in the Russian sector of the World Wide Web.
^ Table 1.2. Windows encoding 1251
Another common encoding is called KOI-8. (code of information exchange, eight-digit) - its origin dates back to the time of the action of the Council for Mutual Economic Assistance of Eastern European States (Table 1.3). On the basis of this encoding, the KOI8-R (Russian) and KOI8-U (Ukrainian) encodings are currently in force. Today, KOI8-P encoding is widely used in computer networks in Russia and in some services of the Russian Internet sector. In particular, in Russia it is de facto standard in communications. email and teleconferencing.
The international standard in which the encoding of the characters of the Russian alphabet is provided is called the ISO encoding. (International Standard Organization - International Institute of Standardization). In practice, this encoding is rarely used (table 1.4).
^ Table 1.3. KOI-8 encoding
![]()
Table 1.4. ISO encoding

On computers working in operating systems MS-DOS, two more encodings may apply (encoding GOST and coding GOST-alternative).The first of them was considered obsolete even in the early years of the advent of personal computing, but the second is still used today (see Table 1.5).
^ Table 1.5. GOST-alternative encoding

In connection with the abundance of text data coding systems operating in Russia, the problem of intersystem data transformation arises - this is one of the most common computer science tasks.
^ Universal text data coding system
If we analyze the organizational difficulties associated with the creation of a unified coding system for text data, we can conclude that they are caused by a limited set of codes (256). At the same time, it is obvious that if, for example, encoding characters is not eight-bit binary numbers, but numbers with a large number of digits, then the range of possible code values will become much larger. Such a system, based on 16-bit character encoding, is called universal - UNICODE. Sixteen digits allow you to provide unique codes for 65,536 different characters - this field is enough to fit most symbols of the planet in one table of characters.
Despite the trivial obviousness of such an approach, a simple mechanical transition to this system was held back for a long time due to insufficient resources of computer equipment (in the coding system UNICODE all text documents automatically become twice as long). In the second half of the 90s, technical means reached the required level of resource endowment, and today we are witnessing a gradual transfer of documents and software to a universal coding system. For individual users, this added even more concern for the coordination of documents executed in different coding systems with software, but this should be understood as the difficulties of the transition period.
^ Graphics coding
If you look at a black and white graphic image printed in a newspaper or book with a magnifying glass, you can see that it consists of the smallest points that form a characteristic pattern called raster (Fig. 1.9).

Fig. 1.9. Raster is a method of encoding graphic information that has long been adopted in the printing industry.
Since the linear coordinates and individual properties of each point (brightness) can be expressed using integers, we can say that raster coding allows the use of binary code to represent graphic data. The generally accepted today is the representation of black and white illustrations in the form of a combination of dots with 256 gradations of gray, and thus, an eight-digit binary number is usually enough to encode the brightness of any point.
For coding color graphics used principle of decomposition any color on the main components. As such components use three primary colors: red (Red, R), green (Green, G) and blue (Blue, B). In practice, it is believed (although theoretically it is not quite so) that any color visible to the human eye can be obtained by mechanically mixing these three primary colors. Such a coding system is called a system. Rgb by the first letters of the names of the primary colors.
If for coding the brightness of each of the main components to use 256 values (eight binary digits), as is customary for half-tone black and white images, then it is necessary to spend 24 bits on coding the color of one point. In this case, the coding system provides an unambiguous definition of 16.5 million different colors, which is actually close to the sensitivity of the human eye. The mode of representing color graphics using 24 bits is called full color (true color).
Each of the primary colors can be assigned an additional color, that is, a color that complements the base color to white. It is easy to see that for any of the primary colors, an additional color will be formed by the sum of the pair of other primary colors. Accordingly, additional colors are: blue (Cyan, C), purple (Magenta, M) and yellow ( Yellow, Y). The principle of decomposition of an arbitrary color into its components can be applied not only to the primary colors, but also to additional ones, that is, any color can be represented as a sum of the cyan, magenta, and yellow components. This method of color coding is adopted in the printing industry, but the fourth paint is also used in the printing industry - black (Black, K). therefore this system coding is indicated by four letters CMYK (black is indicated by the letter TO, because the letter AT is already occupied in blue), and to represent color graphics in this system, you must have 32 binary digits. This mode is also called full color (true color).
If you reduce the number of binary digits used to encode the color of each point, you can reduce the amount of data, but the range of coded colors will be significantly reduced. Color graphics coding by 16-bit binary numbers is called a mode High color.
When encoding color information using eight bits of data, only 256 colors can be transmitted. This color coding method is called index. The meaning of the name is that since 256 values are completely insufficient to convey the whole range of colors available to the human eye, the code of each dot of the raster expresses not the color itself, but only its number (index)in some kind of reference table called palette. Of course, this palette should be attached to graphic data - without it, you cannot use the methods of playing information on the screen or paper (that is, you can use it, of course, but due to incomplete data, the information obtained will not be adequate: the foliage on the trees may turn red. and the sky - green).
^ Audio Coding
Techniques and methods of working with sound information came to computer technology the latest. Moreover, in contrast to numerical, textual and graphical data, sound recordings did not have an equally long and verified coding history. As a result, methods for encoding audio information by binary code are far from standardization. Many individual companies have developed their corporate standards.
The creator of the sites always faces the problem: in what encoding to create a project. In the Russian-language Internet, two encodings are used:
UTF-8 (from English Unicode Transformation Format) - is now a common encoding that implements the Unicode representation, compatible with 8-bit text encoding.
Windows-1251 (or cp1251) - character set and encoding, which is a standard 8-bit encoding for all Russian versions of Microsoft Windows.
UTF-8 is more promising. But every thing has flaws. And the decision to use some kind of encoding just because it is promising, without taking into account many other factors, does not seem to be correct. The choice will be optimal only when it fully takes into account all the nuances of a particular project. Another thing is that to provide all the nuances - in itself is not very simple.
We believe that using UTF-8 is preferable, but deciding what to choose is the business of the project developer. And to facilitate this choice, use the comparative table of the features of both encodings.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
How to translate a site from win1251 to UTF-8
General procedure:
1. Recode the entire database to UTF-8 (most likely you will have to contact the server administrator for help).
2. Recode all site files to UTF-8 (you can do it yourself).
3. Add the following lines to the /bitrix/php_interface/dbconn.php file:
4. Add the following lines to the /.htaccess file:
Php_value mbstring.func_overload 2 php_value mbstring.internal_encoding UTF-8
You can recode all site files to UTF-8 (second item) by running the command via SSH in the root folder of the site:
Find. -name "* .php" -type f -exec iconv -fcp1251 -tutf8 -o / tmp / tmp_file () \\; -exec mv / tmp / tmp_file () \\;