Кодування виндовс 1 251 таблиця
Кодування windows 1 251 була створена на початку 90 років для русифікації програмних продуктів, що випускаються корпорацією Microsoft:
Кодування є 8-бітної і включає в себе символи слов'янської групи мов, в яку входять російський, білоруський, український, болгарський, македонський, сербський - це дає перевагу перед іншими кириличними кодуваннями ( ISO 8859-5, KOI8-R, CP866). Однак у 1251-кодування є і вагомі недоліки:
- 0xFF (25510) - це код, який зарезервований для символу «я». У програмах, які не підтримують чистий 8-ий біт, часто виникають непередбачувані проблеми;
- Немає псевдографіки, яка присутня в KOI8, CP866.
Нижче наведені символи з Code Page 1251 або скорочено СР1251 ( числа під символами є кодом в шістнадцятковій системі такого ж символу в Юникоде):
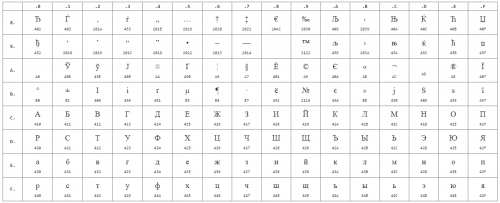
Нерідко у web-розробників і блогерів, які мають різною кваліфікацією виникає проблема з кодуванням сторінок: замість підготовленого тексту з'являються невідомі, нечитабельним символи. Щоб розібратися з даною проблемою, необхідно розуміти суть терміна « кодування сторінки».
Текст в пам'яті комп'ютера зберігається у вигляді певної кількості байт, а не в тому вигляді, в якому він відображається в текстовому редакторі. Кожен байт є кодом, який відповідає одному символу. Для того щоб текст на сторінці відображався як слід, потрібно повідомити браузеру, яку таблицю кодів для розшифровки і відображення він повинен використовувати.
Таблиця кодувань не є універсальною, тобто, для розшифровки тексту необхідно використовувати ту, яка відповідає кодуванні символів:

Для того щоб html-документ коректно відобразився в браузері, необхідно вказати використовувану кодування. Робиться це в такий спосіб:
між тегом
і закриває його потрібно прописати - виходячи з цього рядка, браузер буде використовувати символи російського алфавіту для відображення тексту на сторінці.Кодування windows 1251 до PHP
Ні для кого не є таємницею, що генерація сторінок проходить шляхом вибірки і використання якоїсь частини інформації, яка зберігається в базі даних. При написанні сайту на PHP, найчастіше це mysql.
носії даних
Дані - діалектична складова частина інформації. Вони являють собою зареєстровані сигнали. При цьому фізичний метод реєстрації може бути будь-яким: механічне переміщення фізичних тіл, зміна їх форми або параметрів якості поверхні, зміна електричних, магнітних, оптичних характеристик, хімічного складу і (або) характеру хімічних зв'язків, зміна стану електронної системи і багато іншого.
Відповідно до методу реєстрації дані можуть зберігатися і транспортуватися на носіях різних видів. Найпоширенішим носієм даних, хоча і не самим економічним, мабуть, є папір. На папері дані реєструються шляхом зміни оптичних характеристик її поверхні. Зміна оптичних властивостей (зміна коефіцієнта відбиття поверхні в певному діапазоні довжин хвиль) використовується також в пристроях, які здійснюють запис лазерним променем на пластмасових носіях з відбиваючим покриттям ( CD-ROM). В якості носіїв, що використовують зміна магнітних властивостей, можна назвати магнітні стрічки і диски. Реєстрація даних шляхом зміни хімічного складу поверхневих речовин носія широко використовується у фотографії. На біохімічному рівні відбувається накопичення та передача даних в живій природі.
Носії даних цікавлять нас не самі по собі, а остільки, оскільки властивості інформації досить тісно пов'язані з властивостями її носіїв. Будь-який носій можна характеризувати параметром роздільної здатності (Кількістю даних, записаних в прийнятій для носія одиниці виміру) і динамічним діапазоном (Логарифмическим ставленням інтенсивності амплітуд максимального і мінімального реєстрованого сигналів). Від цих властивостей носія нерідко залежать такі властивості інформації, як повнота, доступність і достовірність. Так, наприклад, ми можемо розраховувати на те, що в базі даних, що розміщується на компакт-диску, простіше забезпечити повноту інформації, ніж в аналогічної за призначенням базі даних, розміщеної на гнучкому магнітному диску, оскільки в першому випадку щільність запису даних на одиниці довжини доріжки набагато вище. Для звичайного споживача доступність інформації в книзі помітно вище, ніж тієї ж інформації на компакт-диску, оскільки не всі споживачі мають необхідним обладнанням. І, нарешті, відомо, що візуальний ефект від перегляду слайда в проекторі набагато більше, ніж від перегляду аналогічної ілюстрації, надрукованій на папері, оскільки діапазон яскравості сигналів в світлі на два-три порядки більше, ніж у відбитому.
Завдання перетворення даних з метою зміни носія відноситься до однієї з найважливіших завдань інформатики. У структурі вартості обчислювальних систем пристрої для введення і виведення даних, що працюють з носіями інформації, складають до половини вартості апаратних засобів.
^ Операції з даними
В ході інформаційного процесу дані перетворюються з одного виду в інший за допомогою методів. Обробка даних включає в себе безліч різних операцій. У міру розвитку науково-технічного прогресу і загального ускладнення зв'язків у людському суспільстві трудовитрати на обробку даних неухильно зростають. Перш за все, це пов'язано з постійним ускладненням умов управління виробництвом і суспільством. Другий фактор, що також викликає загальне збільшення обсягів оброблюваних даних, теж пов'язаний з науково-технічним прогресом, а саме з швидкими темпами появи і впровадження нових носіїв інформації, засобів зберігання і доставки даних.
У структурі можливих операцій з даними можна виділити наступні основні:
збір даних - накопичення даних з метою забезпечення достатньої повноти інформації для прийняття рішень;
формалізація даних - приведення даних, що надходять з різних джерел, до однакової форми, щоб зробити їх порівнянними між собою, тобто підвищити їх рівень доступності;
фільтрація даних - відсіювання «зайвих» даних, в яких немає необхідності для прийняття рішень; при цьому повинен зменшуватися рівень «шуму», а достовірність та адекватність даних повинні зростати;
сортування даних - впорядкування даних за заданою ознакою з метою зручності використання; підвищує доступність інформації;
угруповання даних - об'єднання даних за заданим ознакою з метою підвищення зручності використання; підвищує доступність інформації;
архівація даних - організація збереження даних в зручній та доступній формі; служить для зниження економічних витрат на зберігання даних і підвищує загальну надійність інформаційного процесу в цілому;
захист даних - комплекс заходів, спрямованих на запобігання втрати, відтворення та модифікації даних;
транспортування даних - прийом і передача (доставка і постачання) даних між віддаленими учасниками інформаційного процесу; при цьому джерело даних в інформатиці прийнято називати сервером, а споживача - клієнтом;
перетворення даних - переклад даних з однієї форми в іншу або з однієї структури в іншу. Перетворення даних часто пов'язано зі зміною типу носія, наприклад книги можна зберігати в звичайній паперовій формі, але можна використовувати для цього і електронну форму, і мікрофотопленку. Необхідність в багаторазовому перетворенні даних виникає також при їх транспортуванні, особливо якщо вона здійснюється засобами, не призначеними для транспортування даного виду даних. Як приклад можна згадати, що для транспортування цифрових потоків даних по каналах телефонних мереж (які спочатку були орієнтовані тільки на передачу аналогових сигналів у вузькому діапазоні частот) необхідно перетворення цифрових даних в якусь подобу звукових сигналів, чим і займаються спеціальні пристрої - телефонні модеми.
^ Кодування даних двійковим кодом
Для автоматизації роботи з даними, що відносяться до різних типів, дуже важливо уніфікувати їх форму представлення - для цього зазвичай використовується прийом кодування, тобто вираз даних одного типу через дані іншого типу. природні людські мови - це не що інше, як системи кодування понять для вираження думок за допомогою мови. До мов близько прилягають азбуки (Системи кодування компонентів мови за допомогою графічних символів). Історія знає цікаві, хоча й невдалі спроби створення «універсальних» мов і абеток. Мабуть, безуспішність спроб їх впровадження пов'язана з тим, що національні та соціальні освіти природним чином розуміють, що зміна системи кодування громадських даних неодмінно призводить до зміни суспільних методів (тобто норм права і моралі), а це може бути пов'язано з соціальними потрясіннями .
Та ж проблема універсального засобу кодування досить успішно реалізується в окремих галузях техніки, науки і культури. Як приклади можна привести систему запису математичних виразів, телеграфну абетку, морську прапорцевим абетку, систему Брайля для сліпих і багато іншого.
Мал. 1.8. Приклади різних систем кодування
Своя система існує і в обчислювальній техніці - вона називається двійковим кодуванням і заснована на представленні даних послідовністю усього двох знаків: 0 та 1. Ці знаки називаються двійковими цифрами, по англійськи - binary digit, або, скорочено, bit (біт).
Одним бітом можуть бути виражені два поняття: 0 або 1 (даабо немає, чорне або біле, істинаабо брехняі т.п.). Якщо кількість бітів збільшити до двох, то вже можна висловити чотири різних поняття:
Трьома бітами можна закодувати вісім різних значень:
000 001 010 01l 100 101 110 111
Збільшуючи на одиницю кількість розрядів в системі двійкового кодування, ми збільшуємо в два рази кількість значень, яке може бути виражено в даній системі.
^ Кодування цілих і дійсних чисел
Для кодування цілих чисел від 0 до 255 достатньо мати 8 розрядів двійкового коду (8 біт).
0000 0000 = 0
…………………
1111 1110 = 254
1111 1111 = 255
Шістнадцять біт дозволяють закодувати цілі числа від 0 до 65535, а 24 біта - вже понад 16,5 мільйона різних значень.
Для кодування дійсних чисел використовують 80-розрядне кодування. При цьому число попередньо перетвориться в нормалізовану форму:
3,1415926 = 0,31415926 10 1
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 9
Перша частина числа називається мантиссой, а друга - характеристикою. Більшу частину з 80 біт відводять для зберігання мантиси (разом зі знаком) і якийсь фіксована кількість розрядів відводять для зберігання характеристики (теж зі знаком).
^ Кодування текстових даних
Якщо кожному символу алфавіту зіставити певне ціле число (наприклад порядковий номер), то за допомогою двійкового коду можна кодувати і текстову інформацію. Восьми двійкових розрядів достатньо для кодування 256 різних символів. Цього вистачить, щоб висловити різними комбінаціями восьми бітів все символи англійської та російської алфавітів, як малі, так і великі, а також знаки пунктуації, символи основних арифметичних дій і деякі загальноприйняті спеціальні символи, Наприклад символ «§».
Технічно це виглядає дуже просто, проте завжди існували досить вагомі організаційні складності. У перші роки розвитку обчислювальної техніки вони були пов'язані з відсутністю необхідних стандартів, а в даний час викликані, навпаки, достатком одночасно діючих і суперечливих стандартів. Для того щоб весь світ однаково кодували текстові дані, потрібні єдині таблиці кодування, а це поки неможливо через суперечності між символами національних алфавітів, а також протиріч корпоративного характеру.
Для англійської мови, який захопив де-факто нішу міжнародного засобу спілкування, протиріччя вже зняті. Інститут стандартизації США (ANSI - American National Standard Institute) ввів в дію систему кодування ASCII (American Standard Code for Information Interchange - стандартний код інформаційного обміну США). В системі ASCII закріплені дві таблиці кодування: базова і розширена. Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів з номерами від 128 до 255.
Перші 32 коду базової таблиці, починаючи з нульового, віддані виробникам апаратних засобів (в першу чергу виробникам комп'ютерів і друкуючих пристроїв). У цій області розміщуються так звані керуючі коди,яким не відповідають ніякі символи мов, і, відповідно, не отримали ці коди виводяться ні на екран, ні на пристрої друку, але ними можна керувати тим, як проводиться висновок інших даних.
Починаючи з коду 32 по код 127 розміщені коди символів англійського алфавіту, розділових знаків, цифр, арифметичних дій і деяких допоміжних символів. Базова таблиця кодування ASCII приведена в таблиці 1.1.
^ Таблиця 1.1. Базова таблиця кодування ASCII

Аналогічні системи кодування текстових даних були розроблені і в інших країнах. Так, наприклад, в СРСР в цій області діяла система кодування КОИ-7 (Код обміну інформацією, семизначний). Однак підтримка виробників обладнання та програм вивела американський код ASCII на рівень міжнародного стандарту, І національним системам кодування довелося «відступити» в другу, розширену частину системи кодування, що визначає значення кодів з 128 по 255. Відсутність єдиного стандарту в цій галузі призвело до множинності одночасно діючих кодувань. Тільки в Росії можна вказати три діючих стандарту кодування і ще два застарілих.
Так, наприклад, кодування символів російської мови, відома як кодування Windows-1251, була введена «ззовні» - компанією Microsoft, але, з огляду на широке поширення операційних систем і інших продуктів цієї компанії в Росії, вона глибоко закріпилася і знайшла широке поширення (таблиця 1.2). Ця кодування використовується на більшості локальних комп'ютерів, що працюють на платформі Windows. Де-факто вона стала стандартною в російському секторі World Wide Web.
^ Таблиця 1.2. Кодування Windows 1251
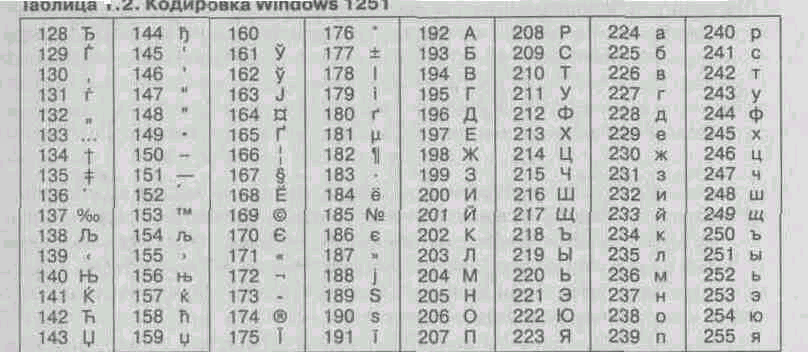
Інша поширена кодування носить назву КОИ-8 (Код обміну інформацією, восьмизначний) - її походження відноситься до часів дії Ради Економічної Взаємодопомоги держав Східної Європи (таблиця 1.3). На базі цієї кодування нині діють кодування КОІ8-Р (російська) і КОІ8-У (українська). Сьогодні кодування КОІ8-Р має широке поширення в комп'ютерних мережах на території Росії і в деяких службах російського сектора Інтернету. Зокрема, в Росії вона де-факто є стандартною в повідомленнях електронної пошти і телеконференцій.
Міжнародний стандарт, в якому передбачена кодування символів російського алфавіту, носить назву кодування ISO (International Standard Organization - Міжнародний інститут стандартизації). На практиці дана кодування використовується рідко (таблиця 1.4).
^ Таблиця 1.3. Кодування ЯКІ-8
![]()
Таблиця 1.4. Кодування ISO

На комп'ютерах, що працюють в операційних системах MS-DOS, можуть діяти ще два кодування (кодування ГОСТ і кодування ГОСТ-альтернативна).Перша з них вважалася застарілою навіть в перші роки появи персональної обчислювальної техніки, але друга використовується і до цього дня (див. Таблицю 1.5).
^ Таблиця 1.5. ГОСТ-альтернативне кодування

У зв'язку з великою кількістю систем кодування текстових даних, що діють в Росії, виникає задача межсистемного перетворення даних - це одна з поширених завдань інформатики.
^ Універсальна система кодування текстових даних
Якщо проаналізувати організаційні труднощі, пов'язані зі створенням єдиної системи кодування текстових даних, то можна прийти до висновку, що вони викликані обмеженим набором кодів (256). У той же час очевидно, що якщо, наприклад, кодувати символи НЕ восьмирозрядних двійковими числами, а числами з великою кількістю розрядів, то і діапазон можливих значень кодів стане набагато більше. Така система, заснована на 16-розрядному кодуванні символів, отримала назву універсальної - UNICODE. Шістнадцять розрядів дозволяють забезпечити унікальні коди для 65536 різних символів - цього поля досить для розміщення в одній таблиці символів більшості мов планети.
Незважаючи на тривіальну очевидність такого підходу, простий механічний перехід на дану систему тривалий час стримувався через недостатні ресурсів засобів обчислювальної техніки (під час передачі сигналу UNICODE всі текстові документи автоматично стають вдвічі довше). У другій половині 90-х років технічні засоби досягли необхідного рівня забезпеченості ресурсами, і сьогодні ми спостерігаємо поступове переведення документів і програмних засобів на універсальну систему кодування. Для індивідуальних користувачів це ще більше додало турбот за погодженням документів, виконаних в різних системах кодування, з програмними засобами, але це треба розуміти як труднощі перехідного періоду.
^ Кодування графічних даних
Якщо розглянути за допомогою збільшувального скла чорно-біле графічне зображення, надруковане в газеті чи книзі, то можна побачити, що воно складається з найдрібніших точок, що утворюють характерний візерунок, званий растром (Рис. 1.9).

Мал. 1.9. Растр - це метод кодування графічної інформації, здавна прийнятий в поліграфії
Оскільки лінійні координати й індивідуальні властивості кожної точки (яскравість) можна виразити за допомогою цілих чисел, то можна сказати, що растрове кодування дозволяє використовувати двійковий код для представлення графічних даних. Загальноприйнятим на сьогоднішній день вважається уявлення чорно-білих ілюстрацій у вигляді комбінації точок з 256 градаціями сірого кольору, і, таким чином, для кодування яскравості будь-якої точки зазвичай досить восьмирозрядного двійкового числа.
Для кодування кольорових графічних зображень застосовується принцип декомпозиції довільного кольору на основні складові. В якості таких складових використовують три основні кольори: червоний (Red, R), зелений (Green, G) і синій (Blue, В). На практиці вважається (хоча теоретично це не зовсім так), що будь-який колір, видимий людським оком, можна отримати шляхом механічного змішування цих трьох основних кольорів. Така система кодування називається системою RGB за першими літерами назв основних кольорів.
Якщо для кодування яскравості кожної з основних складових використовувати по 256 значень (вісім двійкових розрядів), як це прийнято для напівтонових чорно-білих зображень, то на кодування кольору однієї точки треба затратити 24 розряду. При цьому система кодування забезпечує однозначне визначення 16,5 млн різних квітів, що насправді близько до чутливості людського ока. Режим подання кольорової графіки з використанням 24 двійкових розрядів називається повнокольоровим (True Color).
Кожному з основних кольорів можна поставити у відповідність додатковий колір, тобто колір, що доповнює основний колір до білого. Неважко помітити, що для будь-якого з основних кольорів додатковим буде колір, утворений сумою пари інших основних кольорів. Відповідно, додатковими кольорами є: блакитний (Cyan, З), пурпурний (Magenta, М) і жовтий ( Yellow, Y). Принцип декомпозиції довільного кольору на складові компоненти можна застосовувати не тільки для основних кольорів, а й для додаткових, тобто будь-який колір можна представити у вигляді суми блакитної, пурпурової і жовтої складової. Такий метод кодування кольору прийнятий в поліграфії, але в поліграфії використовується ще і четверта фарба - чорна (Black, К). Тому дана система кодування позначається чотирма літерами CMYK (Чорний колір позначається буквою К, бо буква В вже зайнята синім кольором), і для подання кольорової графіки в цій системі треба мати 32 двійкових розряди. Такий режим теж називається повнокольоровим (True Color).
Якщо зменшити кількість двійкових розрядів, використовуваних для кодування кольору кожної точки, то можна скоротити обсяг даних, але при цьому діапазон кодованих квітів помітно скорочується. Кодування кольорової графіки 16-розрядних двійковими числами називається режимом High Color.
При кодуванні інформації про колір за допомогою восьми біт даних можна передати лише 256 колірних відтінків. Такий метод кодування кольору називається індексним. Сенс назви у тому, що, оскільки 256 значень зовсім недостатньо, щоб передати весь діапазон квітів, доступний людському оку, код кожної точки растра виражає не колір сам по собі, а тільки його номер (Індекс)в якійсь довідковій таблиці, званої палітрою. Зрозуміло, ця палітра повинна прикладатися до графічним даними - без неї не можна скористатися методами відтворення інформації на екрані або папері (тобто, скористатися, звичайно, можна, але через неповноту даних отримана інформація не буде адекватною: листя на деревах може виявитися червоною, а небо - зеленим).
^ Кодування звукової інформації
Прийоми і методи роботи із звуковою інформацією прийшли в обчислювальну техніку найбільш пізно. До того ж, на відміну від числових, текстових і графічних даних, у звукозаписів не було настільки ж тривалої і перевіреної історії кодування. У підсумку методи кодування звукової інформації двійковим кодом далекі від стандартизації. Безліч окремих компаній розробили свої корпоративні стандарти.
Перед творцем сайтів завжди встає проблема: в якому кодуванні створювати проект. У російськомовному інтернеті використовуються два кодування:
UTF-8 (Від англ. Unicode Transformation Format) - в даний час поширена кодування, що реалізовує представлення Юнікоду, сумісне з 8-бітовим кодуванням тексту.
Windows-1251 (або cp1251) - набір символів і кодування, що є стандартною 8-бітної кодуванням для всіх російських версій Microsoft Windows.
UTF-8 більш перспективна. Але у будь-якої речі є недоліки. І рішення про використання якоїсь кодування тільки тому, що вона перспективна, без урахування багатьох інших факторів, не представляється правильним. Вибір буде оптимальним тільки тоді, коли він повністю враховує всі нюанси конкретного проекту. Інша справа, що передбачити всі нюанси - саме по собі вельми не просто.
Ми вважаємо, що використання UTF-8 краще, але вирішувати що вибрати - це справа розробника проекту. А для полегшення цього вибору використовуйте порівняльну таблицю особливостей обох кодувань.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Як перевести сайт з кодування win1251 в UTF-8
Загальний порядок дій:
1. Перекодувати всю базу даних в UTF-8 (найімовірніше доведеться звертатися за допомогою до адміністратора сервера).
2. Перекодувати всі файли сайту в UTF-8 (можна зробити своїми силами).
3. У файл /bitrix/php_interface/dbconn.php додати рядки:
4. У файл /.htaccess додати рядки:
Php_value mbstring.func_overload 2 php_value mbstring.internal_encoding UTF-8
Перекодувати всі файли сайту в UTF-8 (другий пункт) можна виконавши команду через SSH в кореневій папці сайту:
Find. -name "* .php" -type f -exec iconv -fcp1251 -tutf8 -o / tmp / tmp_file () \\; -exec mv / tmp / tmp_file () \\;
Днями довелося вирішувати невелику проблему з поганою сприйнятливістю комплекту Denwer до кодування UTF-8. Проблема, чесно кажучи, виявилася дріб'язкова, і була вирішена хвилин за 15, 10 з яких зайняло використання Гугла. У цьому час, досліджуючи різні форуми, я помітив, що для багато хто не може розібратися з цією проблемою досить довго. Крім того, зрозумів, що багатьох цікавить навіщо взагалі використовувати UTF-8, якщо є прекрасна така "російська" кодування Windows-1251. Ось і вирішив написати пару постів на цю тему. Почну я з загального опису даних кодувань, а продовжу, безпосередньо, описом вирішення проблеми використання UTF-8 на пакеті Denwer.
Не так давно, в зв'язку з обставинами, що склалися, вирішив відмовитися від кодування Windows-1251, з якої працював дуже давно, і цілком і повністю перейти на UTF-8. Всі причини переходу розкривати не буду, але основні з них:
- більшість сучасних веб-платформ за замовчуванням працюють саме на ній;
- її дуже зручно використовувати для створення багатомовних проектів;
- набір використовуваних в кодування символів близько 100000;
- кодування універсальна, тобто російські символи і в Нікарагуа залишаються росіянами.
трохи теорії
Windows-1251 - набір символів і кодування, що є стандартною 8-бітної кодуванням для всіх російських версій Microsoft Windows. Користується досить великою популярністю. Windows-1251 вигідно відрізняється від інших 8-бітних кириличних кодувань (таких як CP866, KOI8-R і ISO 8859-5) наявністю практично всіх символів, що використовуються в російській типографике для звичайного тексту; вона також містить всі символи для близьких до російської мови мов: української, білоруської, сербської та болгарського.
UTF-8 - в даний час поширена кодування, що реалізовує представлення Юнікоду, сумісне з 8-бітовим кодуванням тексту. Знайшла широке застосування в операційних системах і веб-просторі. Текст, що складається тільки з символів Юнікоду з номерами менше 128, при записі в UTF-8 перетворюється в звичайний текст ASCII. Решта символів Юнікоду зображуються послідовностями довжиною від 2 до 6 байт.
Основні відмінності кодувань
Головна відмінність кодувань - це використовуваний набір символів. В UTF-8 набагато більше символів можна припустити, що в Windows- 1251. Кодування Windows- 1251 однобайтового, тобто уявити в ній можна тільки 255 символів. Для кирилиці, втім, цього цілком достатньо, саме тому однобайтові кодування досі так масово застосовуються.
Символ в кодуванні UTF-8 може кодуватися аж 6 байтами (поки використовується тільки 4 і більше не планується). Для російської мови, наприклад, символ займає 2 байта. Всі символи, які є в таблиці символів - підтримуються цієї кодуванням. Наприклад, якщо вам потрібен знак копірайту (©), то вам не потрібно шукати особливий шрифт або ж зображати символів в графічному форматі.
Плюси UTF-8:
- UTF-8 дозволяє працювати одночасно з декількома мовами, тобто видавати тексти, в яких використовуються символи різних алфавітів і навіть ієрогліфи. З використанням кодування тисячі двісті п'ятьдесят одна це неможливо;
- використання UTF-8 дозволяє відмовитися від кодових таблиць, Трансляцій символів і всіх інших збочень, що були раніше з однобайтового кодуваннями;
- Немає купи кодувань для одного і того ж мови, як це було раніше для російського: cp1251, cp866, koi8r, iso8859-5.
Мінуси UTF-8 ...
А чи є вони у цій кодування взагалі? Я знаю тільки різних міфах і легендах на цю тему, ось деякі з них: "У UTF-8 є проблеми зі старими браузерами" - малоймовірно ... У всякому разі, якщо під старими не мають на увазі Lynx і Mosaic _); "З UTF-8 виникають проблеми на сервері" - ну да, якщо сервер за замовчуванням намагається визначити інше кодування. Але це не мінус кодування, вже точно ...