Програма для відсканованих документів в ворд. Як виправити відсканований текст
Сканер - пристрій, що розпізнає об'єкти, зображення або документи і записуючий їх візуальний образ в графічний файл, який можна по-різному редагувати. З якою метою зазвичай проводиться дана операція? Як редагувати сканований документ?
Під словом «редагування» слід в даному випадку розуміти:
Редагування як модифікація зображення
Як ми зазначили вище, сканер, обробляючи документ або інший об'єкт, згодом створює на основі його способу статичну картинку у вигляді окремого графічного файлу - наприклад, у форматі Jpeg. Потреби в її редагуванні найчастіше такі:
- поверхнева коригування (зміна розміру, відображення, поворот на задану кількість градусів, настройка колірного балансу);
- редагування елементів зображення (зміна їх зовнішнього вигляду, видалення, додавання нових).
Поверхнева коригування зображення, отриманого зі сканера, може здійснюватися за допомогою найдоступніших видів ПО, які встановлені в Windows за замовчуванням. Який програмою редагувати сканований документ найпростіше? Ймовірно, це буде Paint. Важливі опції редагування файлу знаходяться в меню програми, а також на панелі інструментів її інтерфейсу.
Запустити Paint дуже легко: треба натиснути (в Windows до версії 7 включно) «Пуск», далі - «Усі програми» - «Стандартні» - Paint. Потім за допомогою інтерфейсу даного ПЗ відкриваємо потрібний файл і вносимо в нього необхідні корективи.
Більш складна процедура - редагування елементів зображення - може припускати найширший спектр імовірних операцій: від нанесення невеликій ретуші або букв на картинку до її злиття з іншим графічним файлом у вигляді колажу. Залежно від складності відповідної процедури необхідно буде задіяти той чи інший вид ПО.
Якщо операції з зображенням прості (наприклад, справа обмежується нанесенням букв на нього), то можна використовувати той же Paint. В панелі інструментів даної програми, яка розташовується в її інтерфейсі зліва, потрібно вибрати «Текст». За допомогою нього на зображення наносяться друковані літери.
Редагування текстів і інших об'єктів форматування на зображенні
Як редагувати відскановані документи за допомогою зазначених програм? Дані рішення функціонують так: вони обробляють зображення, розпізнають текст і інші об'єкти форматування, присутні на ньому, а потім заносять їх в окремий файл, який можна, в свою чергу, відкривати за допомогою текстових редакторів - Word, OpenOffice і їх аналогів - і вільно редагувати.
Згодом можна розмістити змінений текст (таблиці, списки) на тому ж відсканованому зображенні, з якого він був в початковому вигляді розпізнано. Для того щоб здійснити цю процедуру, необхідно відкрити відповідний графічний файл в програмі для редагування - наприклад, Paint, в одному вікні, в іншому - розпізнаний і відредагований текст (таблиці, списки). Зробивши друге вікно активним, потрібно виконати скріншот тексту (знімок поточного зображення на екрані монітора) за допомогою клавіші Print Screen Sysrq, після - вставити його в Paint (за допомогою поєднання Ctrl і V), а потім - розмістити на відсканованому зображенні так, як потрібно.
Подібна необхідність може виникнути, наприклад, у дизайнера обкладинки журналу, якому потрібно відредагувати розміщений на ній текст, і якщо у нього з якихось причин немає вихідного файлу. Він може розпізнати потрібні абзаци з паперової сторінки видання, внести в них правки, а потім - знову розмістити їх, вже в зміненому вигляді, на відсканованому зображенні сторінки.
Дуже часто трапляється так, що потрібно відредагувати текст, що міститься тільки в паперовому варіанті. Для розпізнавання і редагування на даний момент є чимало програм, які розрізняються не тільки якістю результатів, але і розширеним функціоналом. Fine Reader є одним з кращих існуючих додатків для виконання цих цілей.
Вам знадобиться
- - текстовий редактор;
- - програма Fine Reader.
Інструкція
Інструкція
Параметр "З сканера або камери" для сканування документів і зображень недоступний в Microsoft Office Word 2007 і Word 2010. Натомість ви можете відсканувати документ за допомогою сканера і зберегти файл на своєму комп'ютері.
Після сканування документа можна за допомогою програми Microsoft Office Document Imaging створити його редагує версію.
важливо: Перш за все потрібно встановити програму Microsoft Office Document Imaging, яка за замовчуванням не встановлена.
Програма Microsoft Office Document Imaging була видалена з Office 2010, однак ви можете встановити її на своєму комп'ютері, використовуючи один з варіантів, описаних в статті Як призначити програму MODI для використання спільно з Microsoft Office 2010.
Перш ніж продовжувати
Установка Microsoft Office Document Imaging
Дотримуйтесь інструкцій для операційної системи, Яка встановлена на вашому комп'ютері.
Windows Vista і Windows 7
Windows XP
Закрийте всі відкриті програми.
Порада: Перед завершенням роботи всіх програм радимо роздрукувати цей розділ.
Натисніть кнопку Пуск і виберіть пункт Панель управління.
на панелі управління виберіть розділ Установка і видалення програм і натисніть кнопку видалити програму.
У списку встановлені програми клацніть встановлений випуск Microsoft Office або додаток Microsoft Office Word 2007 (В залежності від способу установки Word: в складі набору Office або окремо), а потім натисніть кнопку змінити.
Відкривається посібник.
Оберіть Додати або видалити компоненти, А потім натисніть кнопку продовжити.
В розділі параметри установки клацніть знак "плюс" (+) поруч з компонентом засоби Office.
Клацніть стрілку поруч з компонентом Microsoft Office Document Imaging, Виберіть параметр Запускати все з мого комп'ютера, А потім натисніть кнопку продовжити.
Створення редагованого документа
Здійсніть сканування, слідуючи інструкціям для сканера.
Перш ніж продовжувати , Перетворіть отриманий файл в формат TIFF. Для цього можна використовувати Paint або іншу подібну програму.
Тепер у вас є документ, який можна редагувати. Не забудьте зберегти новий файл, Щоб не втратити зміни.
Програми для розпізнавання тексту дозволяють конвертувати сфотографовані або відскановані документи безпосередньо в пропозиції.
Справа в тому, що текст на зображенні представлений у вигляді растра, набору точок. Згаданий софт здійснює перетворення набору точок в повноцінний текст, доступний для редагування і збереження.
Розпізнавання букв покликане оптимізувати процес оцифровки паперових друкованих або рукописних книг, документів.
Такий метод оцифровки на порядки перевершує швидкість ручного набору з зображення. Широко застосовується при оцифрування бібліотек і архівів. Далі розглянемо п'ятірку кращих представників сімейства подібних програм.
ABBYY FineReader 10
FineReader беззаперечний лідер серед усіх програм, які розпізнають текст на зображенні. Зокрема, софта, більш чітко обробного кирилицю немає. Взагалі в активі FineReader 179 мов, текст на яких розпізнається надзвичайно успішно.
Єдина обставина, яка може розчарувати користувачів, полягає в тому, що програма платна. Безкоштовно розповсюджується тільки пробна версія на 15 днів. За цей період дозволено сканування 50-ти сторінок.
Далі за користування програмою доведеться платити. FineReader легко «їсть» будь-яке більш-менш якісне зображення. Джерело при цьому абсолютно не важлива. Будь то фотографія, скан сторінки або будь-яка картинка з буквами.
переваги:
- точне розпізнавання;
- величезну кількість мов читання;
- толерантність до якості зображення-джерела.
недолік:
- пробна версія на 15 днів.
OCR CuneiForm
Безкоштовна програма для зчитування текстової інформації з зображень. Точність розпізнавання на порядок нижче, ніж у попередньої розглянутої програми. Але як для безкоштовної утиліти, функціонал все-таки на висоті.
Цікаво! CuneiForm розпізнає блоки тексту, графічні зображення і навіть різні таблиці. Більш того, зчитуванню піддаються навіть неразлінованной таблиці.
Для забезпечення точності до процесу розпізнавання підключаються спеціальні словники, які поповнюють словниковий запас з сканованих документів.
переваги:
- безкоштовне розповсюдження;
- використання словників для перевірки правильності тексту;
- сканування тексту з ксерокопій поганої якості.
недоліки:
- відносно невелика точність;
- невелика кількість підтримуваних мов.
WinScan2PDF
Це навіть не повноцінна програма, а утиліта. Установка не потрібно, а виконавчий файл важить всього в кілька кілобайт. Процес розпізнавання відбувається гранично швидко, правда, отримані в його результаті документи зберігаються виключно в форматі PDF.
Фактично весь процес виконується при натисканні трьох кнопок: вибір джерела, місця призначення та, власне, запуску програми.
Утиліта призначена для швидкої пакетної обробки безлічі файлів. Для зручності користувачів передбачений великий мовний пакет інтерфейсу.
переваги:
- портативність;
- швидка робота;
- простота у використанні.
недоліки:
- мінімальний розмір;
- єдиний формат файлів на виході.
SimpleOCR
Відмінна невелика програма для розпізнавання текстів з зображень. Підтримує навіть читання рукописів. Біда в тому, що російська не входить ні в мовний пакет інтерфейсу, ні в список підтримуваних для розпізнавання мов.
Однак якщо необхідно відсканувати англійська, датська або французький, то кращого безкоштовного варіанту не знайти.
У своїй області програма забезпечує точну розшифровку шрифтів, видалення шуму і витяг графічних зображень. До того ж в інтерфейс програми вбудований текстовий редактор, практично ідентичний WordPad, що значно підвищує зручність використання програми.
переваги:
- точне розпізнавання тексту;
- зручний текстовий редактор;
- видалення шуму з зображення.
недоліки:
- повна відсутність російської мови.
Freemore OCR
Програма дозволяє оперативно отримувати текст і графіку з зображень. Софт підтримує роботу з декількома сканерами без втрати продуктивності. Видалений текст може бути збережений у форматі текстового документа або документа MS Office.
Крім того передбачена функція багатосторінкового розпізнавання.
Поширюється Freemore OCR безкоштовно, однак, інтерфейс тільки англійською. Але ця обставина ніяк не впливає на зручність користування, тому як організовані елементи управління інтуїтивно зрозумілим чином.
переваги:
- безкоштовне розповсюдження;
- можливість роботи з декількома сканерами;
- гідна точність розпізнавання.
недоліки
- Відсутність російської мови в інтерфейсі;
- Необхідність завантаження російського мовного пакета для розпізнавання.
Після сканування тексту з зображенням виходить графічне зображення документа (графічний образ). Але графічний образ ще не є текстовим документом. Тобто ви не зможете редагувати його содержімое.Проблема розпізнавання тексту в складі точкового графічного зображення є досить сложной.Появілісь так звані системи OCR (Optical Character Recognition - оптичне розпізнавання символів) і спиралися на спеціально розроблені шрифти, що полегшували розпізнавання текстів.
За допомогою програми Fine reader ця проблема легко вирішується. Ця програма призначена для розпізнавання текстів російською, англійською, німецькою, українською, французькою та іншими мовами, а також для розпізнавання змішаних текстів.
Розпізнавання документів в програмі FineReader 7
Після установки програми FineReader в меню Програм Головного меню з'являються пункти, що забезпечують роботу з нею. Вікно програми має типовий для додатків Windows вид і містить рядок меню, ряд панелей інструментів і робочу область.
- У лівій частині робочої області розташовується панель пакет,містить список графічних документів, які повинні бути перетворені в текст. Ці графічні файли розглядаються як частини одного документа. Результати їх обробляються і надалі об'єднуються в єдиний текстовий файл. формазначка, який відзначає вихідні файли, вказує, чи було вироблено розпізнавання.
- Панель в нижній частині робочої області містить фрагмент графічного документа в збільшеному вигляді. З її допомогою можна оцінити якість розпізнавання. Цю панель використовують також при «навчанні» програми в ході розпізнавання.
- Іншу частину робочої області займають вікна документа. Тут розташовується вікно графічного документа, що підлягає розпізнаванню, а також вікно текстового документа, отриманого після розпізнавання.
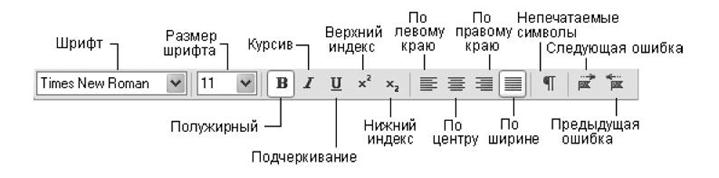
- У верхній частині вікна програми під рядком меню розташовуються панелі інструментів. На наведеному малюнку включено відображення всіх панелей, які можуть бути використані в програмі FineReader.
- Панель інструментів стандартна містить кнопки для відкриття документів і для операцій з буфером обміну. Інші кнопки цієї панелі служать для зміни робочої зони.
- панель Scan & Readмістить кнопки, відповідні етапам перетворення паперового документа в електронний текст. Перша кнопка дозволяє виконати таке перетворення в рамках єдиної операції. Решта кнопки відповідають окремим етапам роботи і містять меню, що розкриваються, службовці для управління відповідною операцією.
- панель зображення використовують при роботі з вихідним зображенням. Зокрема, вона дозволяє управляти сегментацієюдокумента. За допомогою елементів управління цієї панелі задають послідовність фрагментів тексту в підсумковому документі.
- Елементи управління панелі форматування використовують для зміни представлення готового тексту або при його редагуванні.
Як ввести документ за хвилину
- Увімкніть сканер (якщо він має окреме від комп'ютера джерело живлення).
- Увага! Багато моделей сканера необхідно включати до включення комп'ютера.
- Вставте в сканер сторінку, яку Ви хочете розпізнати.
- Натисніть на стрілку праворуч від кнопки Scan & Read, В локальному меню виберіть пункт Майстер Scan & Read.

Майстер Scan & Read викликає спеціальний режим, при якому Ви можете відсканувати і розпізнати сторінку або відкрити і розпізнати графічне зображення (приклад графічного файлу Ви можете знайти в папці Dio. Вона знаходиться в папці, в яку Ви встановили FineReader). При цьому кожен крок супроводжується підказками системи.
Процес введення документів у комп'ютер складається з чотирьох етапів: сканування, розпізнавання, перевірки і збереження результатів розпізнавання.
В результаті сканування з'явиться вікно Зображення, що містить "фотографію" сторінки. Потім програма запропонує Вас встановити параметри розпізнавання і приступить до розпізнавання зображення, одночасно аналізуючи його. Оброблені ділянки зображення зафарбовуються блакитним кольором.
Результат розпізнавання Ви побачите у вікні Текст. У цьому ж вікні Ви можете перевірити і відредагувати розпізнаний текст. Дотримуючись далі за вказівками Мага Scan & Read, Ви можете або передати розпізнаний текст до обраної Вами програми або зберегти його на диску, або продовжити обробку наступних зображень.
параметри сканування
Використовуйте дозвіл 300 dpi для стандартних текстів (розмір шрифту 10pts. І більше) і дозвіл 400-600 dpi для текстів з меншим шрифтом (9pts. І менше). Сканування в сірому режимі рекомендується для підвищення якості розпізнавання. При скануванні в сірому режимі яскравість регулюється автоматично. Якщо Ви хочете, щоб діалог Параметри скануваннявідкривався кожен раз перед скануванням при роботі в режимі - Використовувати інтерфейс FineReader, Меню сервіс— Опції - на закладці сканування/ Відзначте опцію - Діалогове вікно з параметрами перед початком сканування.
- Аналіз оформлення сторінки
Аналіз оформлення сторінки може проходити як вручну, так і автоматично. У більшості випадків програма FineReader сама виконує складну задачу аналізу сторінки. Натисніть кнопку розпізнатидля запуску автоматичного аналізу оформлення сторінки. Розпізнавання і аналіз сторінки виконуються одновременно.Блокамі називаються взяті в рамку ділянки зображення.
Блок тексата - зелений, зображення - червоний, таблиця - синій.
Якщо програма виділила деякі блоки неправильно, простіше і швидше редагувати неправильно розмічені блоки, використовуючи інструмент для редагування блоків, ніж видаляти блоки і виділяти їх заново вручну.
У деяких випадках якість автоматичного аналізу сторінки може бути покращено за допомогою зміни опцій аналізу оформлення сторінки. Для перегляду поточних опцій сторінки меню сервіс— Опції/ закладка розпізнавання.
- Поліпшення якості розпізнавання зображень здвоєних сторінок
Щоб збільшити якість розпізнавання, розбийте скановані зображення так, щоб кожної з пари здвоєних сторінок на зображенні відповідала окрема сторінка пакета. Зображення можуть бути розбиті як автоматично, так і вручну.
Щоб розбивати зображення автоматично перед додаванням в пакет на стрілці біля кнопки сканування/відкритив діалозі Опції, Відзначте опцію - Ділити розворот книги. Щоб розбивати зображення вручну, виберіть параметр - розбити зображенняв меню Зображення.Усунення спотворень, аналіз оформлення сторінки і розпізнавання будуть проходити окремо для кожної сторінки.
- Неправильно відображаються символи
Якщо у вікні текст програми FineReader символи не відображаються належним чином (наприклад, "?" або "?" на місці деяких літер), це означає, що поточний шрифт не підтримує повністю алфавіт обраного Вами мови розпізнавання. Виберіть шрифт, який підтримує всі символи тексту розпізнається (наприклад, Arial Unicode або Bitstream Cyberbit) на закладці форматування(меню властивості— Опції) у групі шрифти, І розпізнайте документ заново.
- Редагування розпізнаного тексту в Microsoft Word
Якщо Ви віддаєте перевагу редагувати розпізнаний текст у Microsoft Word, а не в текстовому вікні програми FineReader, Ви можете зробити так, щоб невпевнено розпізнані символи залишилися підсвіченими. В меню сервісвиберіть пункт формати - на закладці RTF / DOC / Word XML відзначте опцію кольором фону і / або кольором символуу групі - Виділяти невпевнено розпізнані символи. У збереженому файлі все невизначені символи будуть підсвічені обраними Вами на цій закладці квітами.
Тепер давайте зупинимося трохи докладніше на панелях програми і правилах роботи з програмою.
Основні панелі
Головна панель програми Scan & Read
 Майстер Scan & Read- запускає спеціальний режим сканування і розпізнавання, під час якого система контролює дії користувача і підказує йому, що треба робити, щоб отримати той чи інший результат. Сканувати і розпізнати- запускає сканування і розпізнавання документа. Сканувати і розпізнати декілька сторінок- сканує і розпізнає декілька сторінок у циклі.
Майстер Scan & Read- запускає спеціальний режим сканування і розпізнавання, під час якого система контролює дії користувача і підказує йому, що треба робити, щоб отримати той чи інший результат. Сканувати і розпізнати- запускає сканування і розпізнавання документа. Сканувати і розпізнати декілька сторінок- сканує і розпізнає декілька сторінок у циклі.
Відкрити і розпізнати- дозволяє відкрити і розпізнати зображення, вибрані в діалоговому вікні відкрити(Open).

відкрити зображення- додає зображення в пакет, при цьому копія зображення зберігається в папці пакета.
сканувати зображення- сканує зображення. Сканувати кілька сторінок- сканує зображення в циклі. Щоб зупинити сканування, в меню файлвиберіть пункт Зупинити сканування. Опції- відкриває закладку Сканування / Зображення діалогового Опції,на якій Ви може задати параметри сканування і попередньої обробки документа.
розпізнати- розпізнає відкриту сторінку (Або виділені сторінки) пакету.
розпізнати всі- розпізнає всі нерозпізнані сторінки пакета.
Опції- відкриває закладку Розпізнавання діалогу
Опції,на якій Ви може задати параметри розпізнавання документа.
перевірити- дозволяє знайти в тексті слова, що містять невпевнено розпізнані символи, і неправильно написані слова.
 Опції- відкриває закладку Перевірка діалогу Опції,на якій Ви можете задати параметри перевірки документа.
Опції- відкриває закладку Перевірка діалогу Опції,на якій Ви можете задати параметри перевірки документа.
Майстер збереження результатів- відкриває діалог Майстер збереження результатів,в якому Ви можете вибрати програму для збереження і задати параметри збереження.
Передати сторінки в- безпосередньо передає розпізнаний текст до обраної програми без збереження його на диск. При передачі розпізнаного тексту з декількох сторінок пакета спочатку виділіть їх у вікні Пакет.
Передати всі сторінки в- передає всі розпізнані сторінки до обраної програми без збереження їх на диск.
Опції- відкриває закладку Оформлення діалогового Опції,на якій Ви можете задати параметри збереження документа.
панель Зображення

Поради та приклади
PDF документ
Одним з найбільш популярних форматів подання електронних документів в Internet, архівах і т.д. є формат PDF (Portable Document Format).
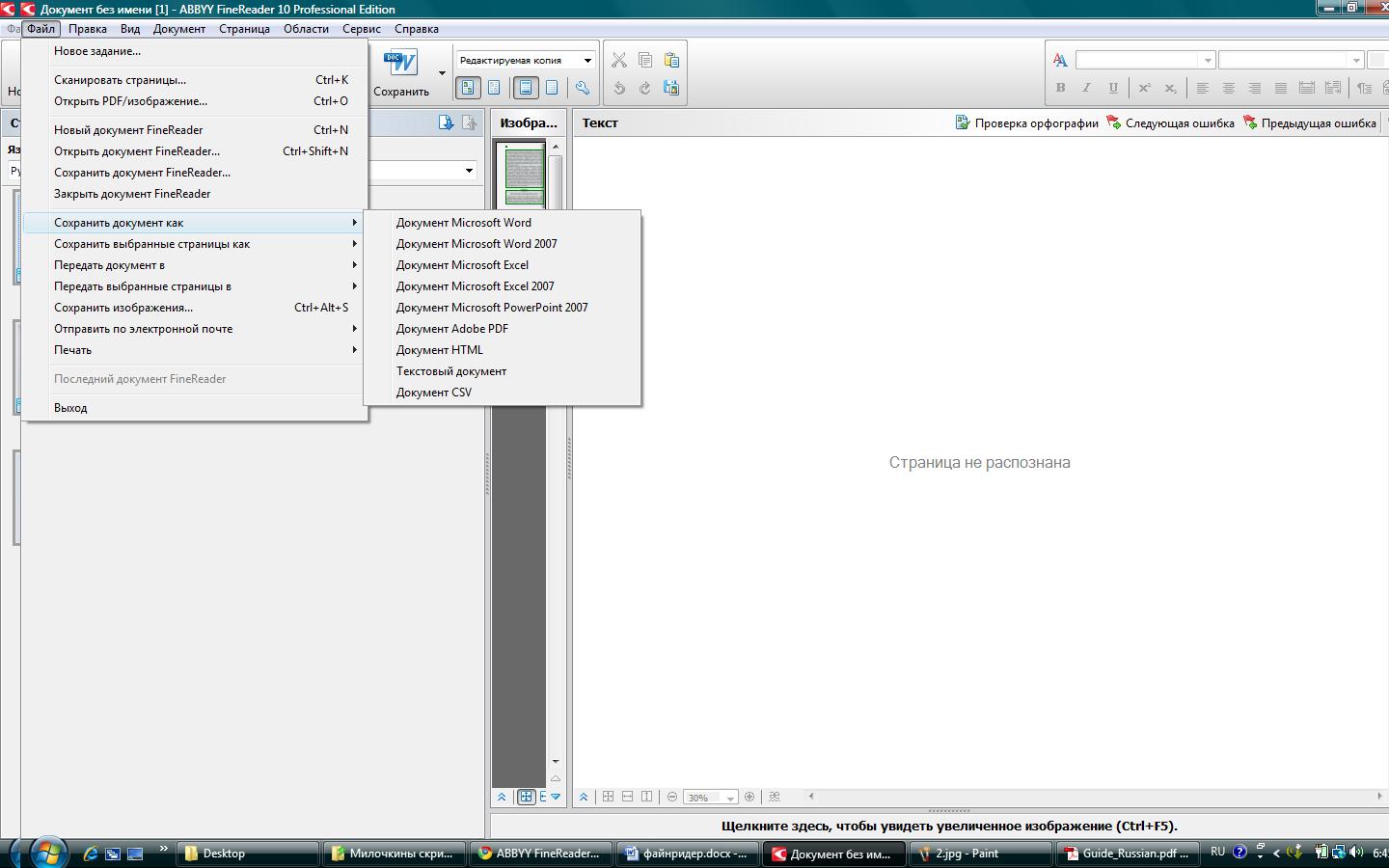
Відкривши PDF-файл в FineReader, Ви можете його розпізнати, відредагувати і зберегти або в PDF, вибравши один з чотирьох режимів збереження оформлення документа (тільки текст і картинки, тільки зображення, текст над зображенням картинки, текст під зображенням картинки), або в будь-якому іншому підтримуваному форматі збереження.
Щоб встановити режими збереження в форматі PDF:
- В меню сервісвиберіть пункт формати.
- на закладці PDF діалогу формативстановіть необхідний режим.
PDF є поширеним форматом для пересилання документів по електронній пошті або публікації документів на web-сайтах. Природно, що при публікації на web-сайтах дуже важлива висока швидкість відкриття документів. Документ, який було збережено з програми FineReader в форматі PDF, відповідає подібним вимогам. Структура PDF така, що дозволяє відкривати в призначеному для користувача браузері для перегляду перші сторінки PDF документа, Не чекаючи, коли весь файл цілком буде завантажений з web-сервера.
Складна журнальна сторінка
 Опис ситуації: погана якість розпізнавання внаслідок неправильного виділення блоків.
Опис ситуації: погана якість розпізнавання внаслідок неправильного виділення блоків.
Рішення: У результаті автоматичного аналізу даної сторінки були виділені зайві блоки (наприклад, ділянки тексту на картинці). Перевірте кількість блоків, а також відредагувати форму виділених блоків.
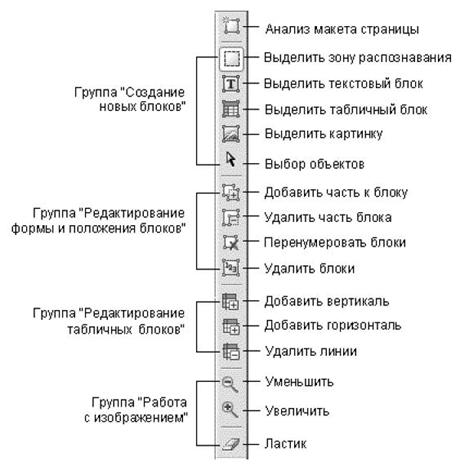
Для цього скористайтеся інструментами на панелі зображення:
зауваження: При виділенні текстових блоків стежте за тим, щоб кордони блоків збігалися з межами тексту.
Книжковий розворот
Опис ситуації: за одне сканування сканується пара сторінок (розворот), при цьому кожна сторінка має свій кут нахилу, що негативно позначається на якості розпізнавання, крім того, обидві сторінки зберігаються на одну сторінку в дві колонки.
 (DualPage.tif) При розпізнаванні зображення повинно мати стандартну орієнтацію: текст повинен читатися зверху вниз, і рядки повинні бути горизонтальними. За замовчуванням при розпізнаванні програма автоматично визначає і коригує орієнтацію зображення. У зображень з парними сторінками стандартна орієнтація відсутня, так як кожна сторінка має свій кут нахилу.
(DualPage.tif) При розпізнаванні зображення повинно мати стандартну орієнтацію: текст повинен читатися зверху вниз, і рядки повинні бути горизонтальними. За замовчуванням при розпізнаванні програма автоматично визначає і коригує орієнтацію зображення. У зображень з парними сторінками стандартна орієнтація відсутня, так як кожна сторінка має свій кут нахилу.
Рішення: У програмі існує спеціальний режим, при якому зображення з парними сторінками розрізається на дві частини і перетворюється в дві окремі сторінки пакету. Це дозволяє обробити кожну сторінку: автоматично виправити кут нахилу і зберегти розпізнаний текст з кожної сторінки в окремий файл (або на окрему сторінку).
- Щоб встановити даний режим, перед додаванням зображення в пакет на закладці Сканування / у групі Обробка зображень відзначте опцію - Ділити розворот книги.
Розрізати зображення з парними сторінками на дві частини, які згодом будуть перетворені в дві окремі сторінки пакету, можна також за допомогою опції - Розбити зображення.
 Візитні картки
Візитні картки
Звичайно, це дуже зручно - вся важлива інформація про людину сконцентрована на листку паперу невеликого формату. Але іноді лякає їх кількість, і ми витрачаємо багато часу для того, щоб їх упорядкувати, привести в систему, знайти зручний засіб зберігання.
Зручний спосіб введення і зберігання візиток в комп'ютері за допомогою програми FineReader. Всі візитки обробляються і зберігаються в пакеті програми. Використовуючи функцію повнотекстового пошуку по розпізнаних сторінок пакета, Ви можете знайти потрібну візитку (при цьому пошук можливий за будь-розпізнаної інформації з візитки - за назвою компанії, прізвища, телефону і т.д.). Список знайдених візиток показується у вікні Пошук. Щоб відкрити візитку, потрібно записати новий в результатах пошуку.
Ви можете поповнювати пакет новими візитками, редагувати вже розпізнані візитки у вікні Текст.
- Покладіть кілька візитних карток (стільки, скільки вміститься) в сканер.
Увага! Візитки повинні бути розкладені так, щоб в результаті була отримана "таблична структура". Між рядами і колонками повинна бути деяка відстань. Припустимо або горизонтальне (довші сторони візиток розташовані уздовж горизонталі), або вертикальне розміщення візиток на аркуші, але не обидва відразу.
Встановіть наступні параметри сканування:
- дозвіл - 400-600 dpi (зазвичай візитні картки містять текст, набраний дрібним шрифтом, Для хорошого розпізнавання якого потрібно відсканувати документ з більш високою роздільною здатністю замість звичайних 300 dpi).
- тип зображення - сірий або кольоровий.
Натисніть кнопку - сканувати.
зауваження: Якщо зображення було поділено на візитні картки невірно, то спробуйте поділити зображення вручну. Для цього скористайтеся кнопками і. Щоб пересунути або видалити роздільник, натисніть кнопку вибір роздільник -, мишею перемістіть роздільник в потрібне місце. Для видалення роздільник перемістіть його за межі зображення. Щоб видалити розділювачі, натисніть кнопку.
- Встановіть мову розпізнавання. Якщо потрібно, встановіть кілька мов. При цьому пам'ятайте, що збільшення кількості підключених до розпізнавання одного документа мов може призвести до погіршення якості розпізнавання. Не рекомендується підключати більш 2-3 мов. Перед запуском розпізнавання перевірте підключені на закладці форматування шрифти: вони повинні містити всі символи мови розпізнавання. У протилежному випадку розпізнаний текст буде неправильно відображений у вікні текст (В словах на місці деяких літер стоять значки "?" Або "?").
- Натисніть кнопку - розпізнати.
програмна роздруківка
Опис ситуації: даний приклад має дві особливості, що впливають на якість розпізнавання:
- програма передає відступи від лівого краю листа не пробілами, а за допомогою завдання відступів абзацу; при експорті в.txt відступ зліва не зберігається; деякі рядки об'єднуються в один абзац і при експорті об'єднуються в один рядок;
- багато помилок при розпізнаванні конструкцій мов програмування.
 Рішення:
Рішення:
- Для розпізнавання таких документів існує спеціальна опція програми Форматований пробілами текст.Встановлюється в групі Тип сторінкина закладці розпізнавання діалогу Опції (меню сервіс — Опції).
В цьому випадку в розпізнаному тексті збережеться поділ на рядки; відступи від лівого краю будуть передані пробілами; кожен рядок виділена в окремий абзац, а відстані між абзацами передані порожніми рядками. Все це дозволить зберегти вихідне форматування тексту при збереженні в форматі Txt.
- Для хорошого розпізнавання роздруківок програм потрібно встановити спеціальну мову розпізнавання. Для цього:
- У списку мов на панелі - стандартна виберіть значення вибір з повного списку мов і в діалозі Мова тексту, що розпізнається виберіть пункт C ++.
зауваження: Якщо розпізнавана програмна роздруківка крім програмного коду містить текстові коментарі, то для хорошого розпізнавання необхідно вибрати кілька мов розпізнавання: мова програмування і мова, на якому написані коментарі.
 Таблиця з неповною кількістю чорних роздільників
Таблиця з неповною кількістю чорних роздільників
Опис ситуації: всі рядки таблиці між чорними горизонтальними лініями (роздільниками) об'єднані в один рядок таблиці.
Якщо в таблиці зустрічається змішане поділ на рядки і стовпці, при якому деякі рядки розділені чорними роздільниками, а деякі ні, програма може розбити таблицю на рядки неправильно.
Рішення: Програму можна "змусити" виділяти кожен рядок тексту в окремий рядок таблиці, зазначивши спеціальну опцію на закладці розпізнавання (меню сервіс — Опції) у групі таблиці: У кожній клітинці таблиці не більше одного рядка тексту.
складна таблиця
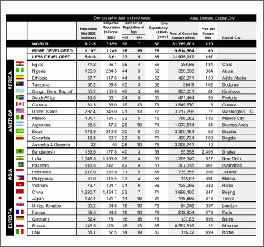 Опис ситуації:неправильний аналіз таблиць зі складною нерегулярної структурою: неправильне поділ таблиці на рядки і стовпці; неправильне виділення картинок в осередках таблиці; погане розпізнавання вертикального і інвертованого тексту.
Опис ситуації:неправильний аналіз таблиць зі складною нерегулярної структурою: неправильне поділ таблиці на рядки і стовпці; неправильне виділення картинок в осередках таблиці; погане розпізнавання вертикального і інвертованого тексту.
РішенняСкористайтеся інструментами ручної розмітки таблиць, розташованими на панелі зображення:
Щоб додати вертикальну лінію;
Щоб додати горизонтальну лінію;
Щоб видалити лінію.
Для елементів таблиці, що містять тільки картинки, в діалозі властивості блоку(меню вид — властивості), Відзначте пункт - Вважати осередок картинкою.
Для виділення картинок всередині осередків з текстом в окремі блоки, скористайтеся інструментом на панелі зображення: .
Для елементів таблиці, що містять вертикальний текст, в діалозі властивості блоку (меню вид — властивості) в полі напрямок тексту вкажіть напрямок тексту в осередку; для осередків з інвертованим текстом відзначте пункт інвертований.
Розглянемо тепер десяту версію програми - вона вміє розпізнавати і фотографії, зняті на звичайні фотоапарати або навіть мобільні телефони з камерою. Розглянемо основні особливості останньої версії ABBYY FineReader.
Сканування і розпізнавання фотографій
В ABBYY FineReader 10 функція розпізнавання фотографій в текст істотно прискорює процес переведення паперового документа в електронний вигляд, так як фотографування паперів і документів здійснюється набагато швидше сканування. Технологія дозволяє перевести в текст навіть зняті на мобільний телефон фотографії з низьким дозволом - від 2 мегапікселів. Крім того, процес прискорюється також за рахунок того, що користувачеві не обов'язково копіювати фотографії з фотоапарата на жорсткий диск ПК. Досить просто скористатися командою «Отримати зображення і розпізнати» при підключеному фотоапараті. При цьому отриманий текст відразу виводиться в вікні текстового редактора.
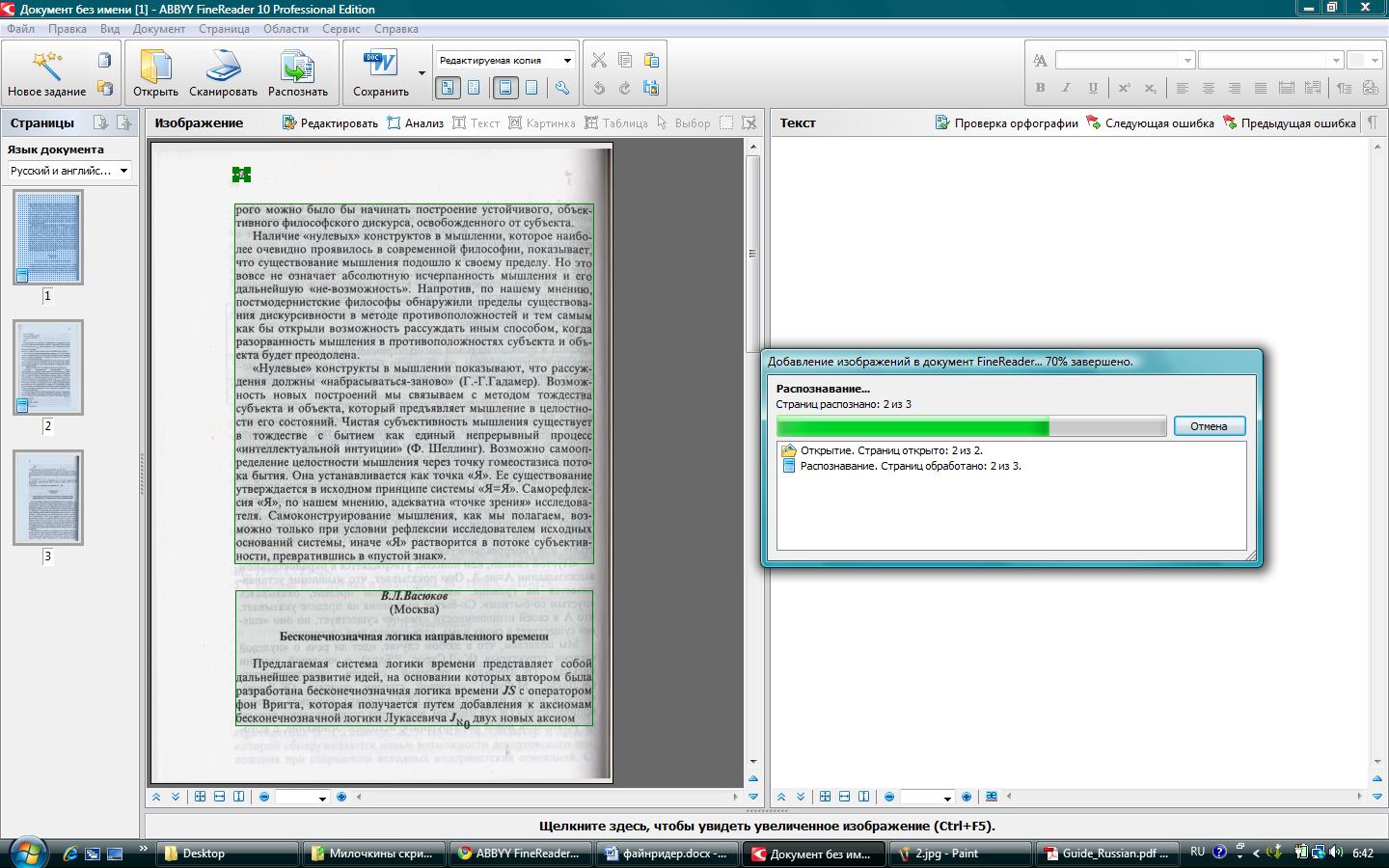
ABBYY FineReader 10 дозволяє в ході підготовки зображення до розпізнавання провести обробку, яка підвищує якість результату роботи OCR-движка. У оброблюваної фотографії можна поліпшити чіткість, застосувати шумозаглушення, виправити деякі види геометричних спотворень, причому ці операції проходять в автоматичному режимі. У попередніх версіях FineReader умовно можна було працювати зі знятими фотографічними зображеннями, проте в цілому, дуже багато залежало від якості зйомки. Так, відзнятий розворот книги міг некоректно сприйматися OCR-механізмом, тому такі сторінки містили «сміття» ближче до згину. У новій версії подібні складнощі подолані - движок автоматично «виправить» невірний кут при зйомки книги.
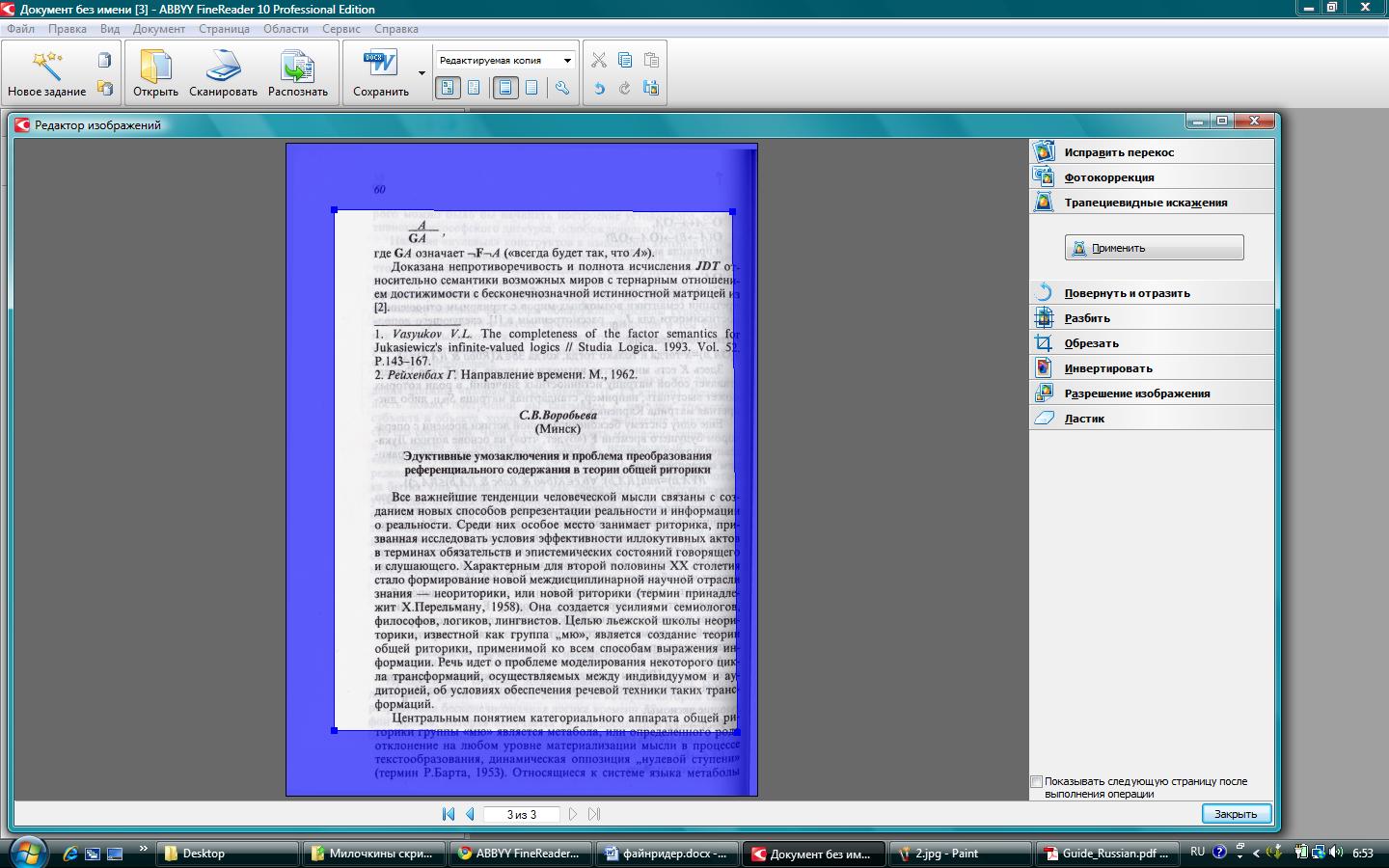
Якщо якість зображення фотографії зовсім погане, то графічним редактором ABBYY FineReader 10 можна користуватися вручну - програма надає можливість регулювати налаштування усунення розмиття, обрізати потрібну частину зображення з точністю до пікселів. Можна редагувати колірний спектр зображення завдяки опції "Інвертувати кольору», а також змінювати якість або видаляти частину непотрібного тексту. Дані настройки зображення, що виставляються в графічному редакторі, можна застосувати автоматично до всіх зображень, імпортованих в програму.
Інтелектуальне розпізнавання елементів і форм
В ABBYY Finereader 10, на відміну від попередніх версій, Покращилася функція визначення структури сканируемого тексту. Це здійснюється завдяки новітній технології адаптивного розпізнавання документів (ADRT - Adaptive Document Recognition Technology), що надається тепер у другій версії (в ABBYY FineReader 9 була ADRT 1.0).
![]()
Текст розпізнається не посторінковий, як раніше, а відразу як єдине ціле. Завдяки цьому відбувається точне визначення всіх елементів тексту, включаючи заголовки, зноски, підписи під картинками, таблиці, колонтитули. Якщо сканування проводиться відразу в певний формат, наприклад MS Word, то підсумковий текстовий документ буде містити необхідні елементи у вигляді відповідних форм, а не просто як текст. Це дуже суттєво спрощує роботу, тому що позбавляє користувача від виконання подальших рутинних операцій щодо форматування в редакторі розпізнаного тексту. У новій версії ADRT дозволяє визначати ще більше елементів форматування тексту, що дозволяє на порядок полегшити процеси вичитки підсумкового документа в текстовому редакторі. ABBYY FineReader 10 крім класичних функцій розпізнавання відсканованого тексту в формати Microsoft Word, Microsoft Excel, PDF, тепер надає можливості сканування в HTML, що дозволяє створювати багатосторінкові зверстані електронні книги зі змістом і розбивкою по главам в вигляді окремих сторінок. Одержаний результат можна скомпілювати, наприклад, для створення файлів довідки.
При процесі розпізнавання використовується перевірка орфографії для основних 39 мов, в тому числі і для декількох «мертвих». Сам же механізм розпізнавання придбав в новій версії підтримку декількох нових мов, довівши загальну кількість до 186. При цьому якість «розуміння» текстів на азіатських мовах покращився на 30%, а на європейських - на 20%.
У десятій версії істотно розширилися можливості роботи з PDF. ABBYY FineReader і раніше дозволяє здійснювати операції з розпізнаванням, пізніше з конвертацією в PDF і з PDF-файлів в популярні офісні формати, проте реалізація подібної функції в додатку мала недостатньо опцій. У новій 10-й версії PDF-файл можна стискати до потрібного розміру, а також переводити в архівний формат PDF / A, який є оптимальним для зберігання PDF-документів. Крім того, при завантаженні програми з'являється інтерактивний майстер з уже встановленим сценарієм автоматичної переконвертації PDF в Word.
Додаткові можливості
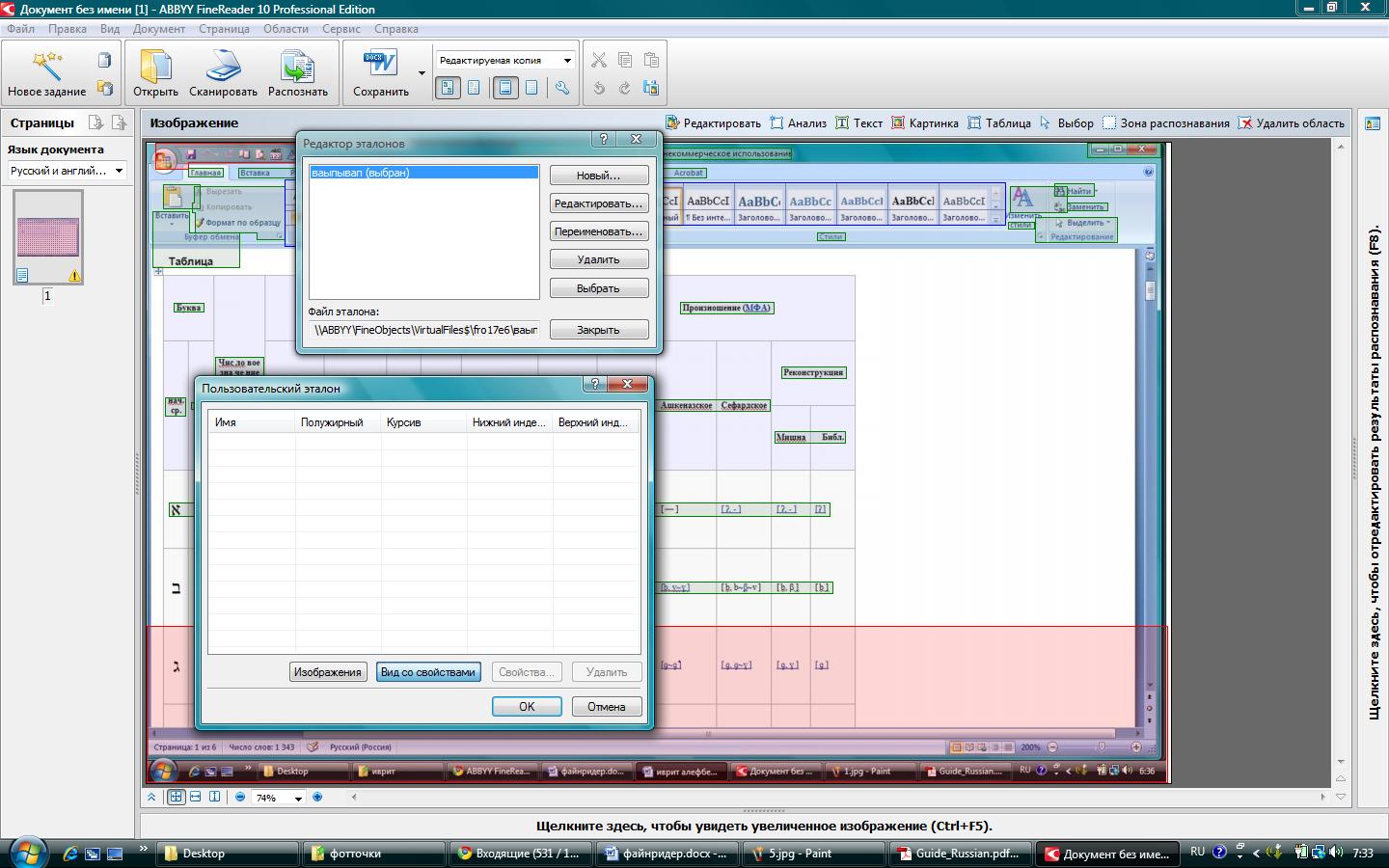
Для того щоб спростити розпізнавання складного і великого за обсягом тексту, що містить велику кількість спеціальних символів або своєрідні шрифти, робить "Розпізнавання з навчанням». Програма пропонує користувачеві створити шаблон, що містить ці нестандартні елементи. Завдяки такому «еталону» ABBYY FineReader 10 може прискорити і оптимізувати розпізнавання залишився обсягу тексту.
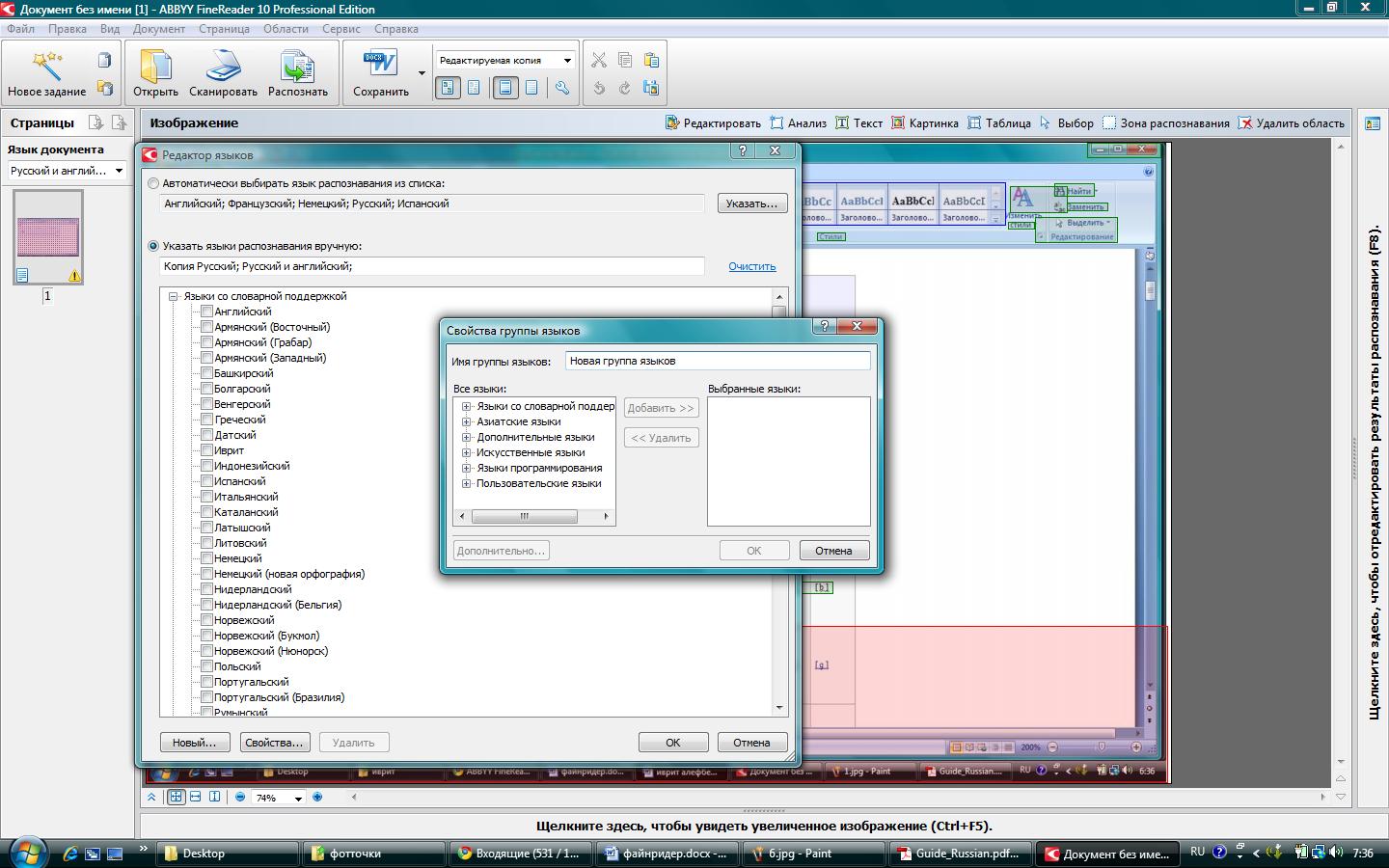
Якщо документ містить відразу кілька мов, то для спрощення роботи можна скористатися функцією об'єднання мов в групи.
Крім того, для оптимізації роботи в ABBYY FineReader 10 можна налаштовувати менеджер сценаріїв відповідно до поставлених цілей. Він передбачає складання послідовності виконання операцій в програмі і аналогічний макросам, наприклад, в MS Word.
Великим плюсом ABBYY FineReader 10 є сумісність з усіма основними платформами, включаючи останню на сьогоднішній день версію Microsoft Windows 7. По суті, серед OCR-продуктів на платформі Windows рішення від компанії ABBYY займає вже тривалий час лідируючі позиції. Умовні «конкуренти» в особі популярних в 1990-х роках додатків для домашніх користувачів, незважаючи на періодичний випуск нових версій, серйозно відстають як за якістю розпізнавання, так і по функціональності. ABBYY FineReader, в свою чергу, в кожній новій версії спрощує роботу користування для перекладу паперових документів в електронні формати, серед яких файли MS Word, PDF і HTML. Особлива відзнака програми від попередніх версій полягає в тому, що користувачеві більше не потрібний сканер, а достатньо найпростішого і дешевого фотоапарата або телефону з камерою, фотографії з якого можуть бути якісно розпізнані. Крім того, подібне рішення працює швидше за попередні версії. Зручний інтерфейс, що підтримує Windows 7, можливість автоматичної і ручної обробки зображень для сканування, покращений механізм аналізу структури документа, що дозволяє створювати електронні книги, - вигідно відрізняє нову версію OCR-програми не тільки від попередніх видань ABBYY FineReader, а й від нечисленних конкурентів.