Найпоширеніша система кодування символів. Що таке кодування символів
Комп'ютери можуть обробляти інформацію тільки в числовій формі. Тому при обробці текстів в комп'ютері кожному символу тексту повинно бути співставлено деяке число. Таблиця відповідності між набором символів і числами (числовими кодами символів) називається кодуванням символів.
Кодування символів використовується при введенні текстів та документів в комп'ютер і при виведенні текстів, повідомлень і документів для читання людиною (наприклад, монітор, принтер і т. Д.).
Зауваження. Таблиці кодування іноді називають кодовими сторінками.
види кодувань
Зараз найбільш поширені два види кодувань:
- однобайтні кодування, в яких для кодування одного символу тексту використовується один байт (8 біт);
- кодування Unicode (Юнікод) - в ній для кодування одного символу тексту використовуються два або чотири байти.
Однобайтні кодування дозволяють закодувати до 256 різних символів (1 байт - це 8 бітів, а 256 - це 28). Такі кодування застосовувалися ще на найперших комп'ютерах, з середини XX століття. До 1990-х років все кодування символів, практично використовувані в комп'ютерах, були однобайтном.
Однобайтні кодування були цілком прийнятні для більшості користувачів - адже 256 кодів символів цілком достатні для кодування текстів на більшості мов. Але, коли комп'ютери стали широко використовуватися в усьому світі, кількість однобайтовим кодувань стало обчислюватися сотнями. Адже мов люди використовують дуже багато, часто ці мови мають свій особливий алфавіт (грецька, єврейська і т. Д.), А тому для них потрібна своя кодування. До того ж, часто для однієї мови входили у вжиток кілька кодувань. Все це стало приводити до складнощів і плутанини, особливо при створенні багатомовних документів і в міжнародному спілкуванні. Тому зараз замість численних однобайтовим кодувань все ширше використовується універсальна кодування Unicode.
Кодування Unicode. В останні роки все більше застосування знаходить кодування Unicode (Юнікод). У ній для кодування кожного символу зазвичай використовується два байта, а для деяких символів - 4 байта (двох байт виявилося мало).
В кодуванні Unicode є коди для практично всіх застосовуваних символів (букв алфавітів різних мов, математичних, декоративних символів і т. д.). Це дуже зручно, тому багато нові програми для кодування текстової інформації використовують кодування Unicode.
А. Альошин
Крім цифр, на монітори ЕОМ необхідно виводити ще й безліч символів. Ясно, що для виведення кожного символу необхідний якийсь машинний код, однозначно відповідає цьому символу, або якесь правило, за яким можна організувати коректний висновок кожного символу на дисплей. Зрозуміло, розробляти таку систему введення-виведення слід оптималь-ним чином з точки зору споживання ресурсів комп'ютера. Особливо важливо в цьому випадку пам'ятати про те, що продуктивність комп'ютерів у віддалені часи зародження обчислюва-лительного техніки була незначною, з сучасних позицій, а системні програмісти і раз-работчікі апаратної частини боролися за кожен біт, адреса, інструкцію, регістр, звільняючи оперативну пам'ять і адресний простір комп'ютерних "малюків".
Давайте підрахуємо, скільки необхідно символів для виведення інформації на дисплей. Історично склалося так, що перші розробники комп'ютерів були носіями англійсько-го мови. Що їм було необхідно забезпечити для виведення на монітор? По-перше, 26 букв анг-лийского алфавіту (малих), по-друге, 26 прописних, 9 знаків пунктуації (.,:! ";? ()), Пробіл, 10 цифр, 5 знаків арифметичних дій (+, -, *, /, ^) і спеціальні символи (№% _ # $, і так далі ^, &,\u003e,<, |, \). Получается чуть больше сотни символов. Такой сравнительно не-большой базовый набор символов можно закодировать при помощи таблиц соответствия этого набора машинным кодам (фактически, двоичным числам). Можно вполне ограничиться набором двоичных чисел от 0 до 27 (всего 128 позиций), что и было сделано. Таблица соответствия полу-чила название ASCII (American Standard Code for Information Interchange). В рамках таблицы ASCII создание многоязычных документов являлось очень проблематичной, а в большинстве случаев и совершенно невыполнимой задачей.
Однак базового набору кодів стало швидко не вистачати. Зрослий дефіцит знакомест в стандартній таблиці ASCII зажадав її негайного розширення. В результаті виникла но-вая таблиця кодувань, що отримала назву "розширена таблиця ASCII", число знакомісць в якій зросла до 28 (256 знакомест). Ця таблиця отримала назву міжнародного стандартами-та IS 646, а восьмібітних код - Latin-1. У нього були додані в основному латинські букви зі штрихами і діакритичні символи. Незабаром з'явився новий стандарт IS 8859, в якому вводь-лось поняття "кодова сторінка", тобто набір з 256 символів для визначення мови або групи мов, тобто IS 8859-1 це Latin-1, IS 8859-2 включав слов'янські мови з латинським алфавітом (чеська, польська, вергерскій), IS 8859-3 включав турецька, мальтійський, есперанто, Галісія-ський мови, і т.д. Недоліком такого підходу є те, що програмне забезпечення має стежити за кодовими сторінками, змішувати мови при цьому неможливо, крім того і не були створені кодові сторінки японської та китайської мов.
У січні 1991 року виник консорціум UNICODE, метою якого є просування, розвиток і реалізація стандарту Unicode як міжнародної системи кодування для обміну інформацією, а також підтримання якості цього стандарту в майбутніх версіях.
Стандарт UNICODE 4.0 являє собою нову систему кодування символів, виводи-дімих на екран монітора або на принтер, що дозволяє закодувати 1 114 112 символів (в стандарті з прийнято називати code points). Більшість символів, що використовуються в основних мовах світу займають 65 536 code points, утворюючи Basic Multilingual Plane (BMP) (Основний Мно-гоязичний Рівень - мій переклад). Решта (понад мільйон) code points цілком достатньо для кодування всіх відомих символів, включаючи малопоширені мови і історичні знаки. Стандарт UNICODE підтримується трьома формами, 32-бітної (UTF-32), 16-бітної (UTF-16) і 8-бітної (UTF-8). Восьмібітного форма UTF-8 була розроблена для зручної совмес-тимость з ASCII-орієнтування системами кодування. Стандарт UNICODE сумісний з Міжнародним стандартом International Standard ISO / IEC 10646.
Найбільш просто влаштована форма UTF-32. У ній кожен символ закодований за допомогою 32-бітного блоку. Завдяки цьому кожен символ UTF-32 володіє однозначним відповідністю між декодувати символом і блоком коду. Це форма має фіксовану довжину знакі-місця. Вона покриває всі кодове простір UNICODE - 0 ... 10FFFF16. Це гарантує пів-ву сумісність з UTF-16 і UTF-8. Форма UTF-32 є найбільш бажаною для більшості UNIX платформ.
Стандарт UNICODE містить 96 382 символу, взятих їх світових шрифтів. Цих симво-лов більш ніж достатоно для спілкування на всіх відомих мовах світу, а також для написання класичних (історичних) шрифтів багатьох мов. UNICODE всключает в себе шрифти їв-ропейскіх алфавітів, середньо-азійський лист, направлений праворуч на ліво, шрифти Азії, і багато інших. Підмножина символів (code points) HUN включає 70 207 идеографических символів визначаються за національними і промисловим стандартам Китаю, Японії, Кореї, Тайвані, В'єтнаму і Сінгапуру. Більш того, UNICODE містить знаки пунктуації, математичного-ські символи, технічні символи, герметріческіе фотми і графічні позначки (dingbats), фо-генетичних знаки.
Система зчислення - символічний метод запису чисел, подання чисел за допомогою письмових знаків.
Система зчислення:
§ дає уявлення безлічі чисел (цілих і / або речових);
§ дає кожному числу унікальну виставу (або, принаймні, стандартний вигляд);
§ відображає алгебраїчну і арифметичну структуру чисел.
Системи числення поділяються на позиційні, непозиційної і змішані.
Чим більше підставу системи числення, тим менша кількість розрядів (тобто записуються цифр) потрібний при запису числа в позиційних системах числення.
Така таблиця зіставляє кожному символу послідовність довжиною в один або кілька байтів.
Хоча термін «набір символів» (англ. character set, charset), Узаконений RFC 2278, зараз є, мабуть, найбільш авторитетним, що передував йому термін «кодування» (англ. encoding) Як і раніше використовується як синонім, зокрема, в мовах програмування,, і.
Нерідко також замість терміна «набір символів» неправильно вживають термін «кодова сторінка», що означає насправді окремий випадок набору символів з однобайтном кодуванням.
В даний час в основному використовуються кодування трьох типів: сумісні з EBCDIC і засновані на Юникоде 16-бітові, з переважною перевагою перших. Подання Юникода сумісно з ASCII. Кодування на базі ДКОИ-8) використовуються тільки на деяких мейнфреймах. Спочатку в кожній операційній системі використовувався один набір символів. Тепер використовувані набори символів, залежать від типу операційної системи лише за традицією і встановлюються відповідно до локалі.
Автоматичне розпізнавання кодувань
Використання безлічі кодувань в сучасному ПО створює багато незручностей не тільки програмістам, але і користувачам. Відповідно до однієї точки зору, впоратися з крокозябра можна, якщо програми будуть автоматично розпізнавати кодування вхідного тексту.
Для однобайтовим кодувань можна враховувати той факт, що частота використання різних букв сильно різниться (наприклад, в російській часто використовується «о», але рідко "ь"). Тому, знаючи мову тексту, можна легко вибрати кодування, в якій частота байтів краще відповідає частоті букв даного мови.
Альтернативна точка зору вважає подібні евристичні алгоритми визначення кодування тексту шкідливими, оскільки сучасні інформаційні технології мають у своєму розпорядженні засобами недвозначно зіставити тексту належну йому кодову сторінку (див., Наприклад, програм створення текстових даних, що порушують стандарти.
поширені кодування
Дивитися що таке "Кодування символів" в інших словниках:
Кодування російської мови в комп'ютерних програмах і в Інтернеті - - Всі символи, які можуть відображатися на екрані комп'ютера, описані в таблиці символів. У самій першій таблиці символів не було російських букв. Для того роботи з російськими буквами їх треба було вписати в цю таблицю символів замість непотрібних ... ... Енциклопедичний словник ЗМІ
Набір символів (англ. Character set) певна таблиця кодування кінцевого безлічі знаків. Така таблиця зіставляє кожному символу послідовність довжиною в один або кілька байтів. Хоча термін «набір символів» (англ. Character set, ... ... Вікіпедія
Перевірити інформацію. Необхідно перевірити точність фактів і достовірність відомостей, викладених у цій статті. На сторінці обговорення повинні бути пояснення. «Альтернативна кодування» підстав ... Вікіпедія
- (англ. Character set) таблиця, що задає кодування кінцевого безлічі символів алфавіту (зазвичай елементів тексту: літер, цифр, розділових знаків). Така таблиця зіставляє кожному символу послідовність довжиною в один або кілька ... ... Вікіпедія
Юнікод, або Унікод (англ. Unicode) стандарт кодування символів, що дозволяє представити знаки практично всіх письмових мов. Стандарт запропонований в 1991 році некомерційною організацією «Консорціум Юнікоду» (англ. Unicode Consortium, ... ... Вікіпедія
Шестібітние кодування застосовувалися в комп'ютерах, які проводилися в США в 1950 х 1960 х роках. Відповідно розмір машинного слова на цих комп'ютерах був кратний 6 біт (наприклад, 12, 18, 24, 36, 48, 60 біт). Такий розмір символу дозволяв ... ... Вікіпедія
Юнікод підтримує практично всі існуючі набори символів. Найкращою формою кодування набору символів Юнікоду є UTF-8-кодування. У ній реалізована сумісність з ASCII, стійкість до спотворення даних, ефективність і простота обробки. Але про все по порядку.
форми кодування
Комп'ютери оперують числами не просто як абстрактними математичними об'єктами, а як комбінаціями одиниць зберігання і обробки інформації фіксованого розміру - байтів і 32-розрядних слів. Стандарт кодування повинен це враховувати при визначенні способу представлення
У комп'ютерних системах цілі числа зберігаються в комірках пам'яті розміром 8 біт (1 байт), 16 або 32 біт. Кожна форма кодування Юнікод визначає, яка послідовність осередків пам'яті представляє ціле число, відповідне конкретному символу. У стандарті представлені три різні форми кодування символів Юнікоду: 8, 16 і 32-бітових блоками. Відповідно, вони звуться UTF-8, UTF-16 і UTF-32. Назва UTF розшифровується як формат перетворення Юнікоду. Кожна з трьох форм кодування є рівноправними засобами представлення символів Юнікоду, має переваги в різних областях застосування.
Дані кодування можуть бути використані для подання всіх символів стандарту Юнікод. Таким чином, вони повністю сумісні для рішень, з різних причин використовують різні форми кодування. Кожна кодування може бути однозначно перетворена в будь-яку з двох інших без втрати даних.
принцип ненакладення
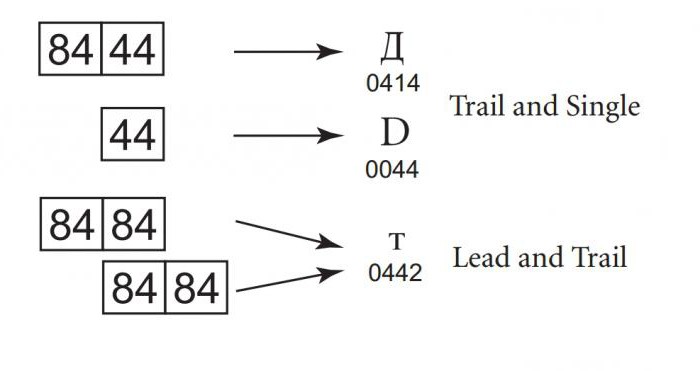
Кожна з форм кодування Юнікоду розроблена з урахуванням неприпустимість часткового накладення. Наприклад, Windows-932 формує символи з одного або двох байтів коду. Довжина послідовності залежить від першого байта, тому значення лідируючого байта в послідовності з двох байтів і одиночного байта не перетинаються. Однак значення одиночного байта і замикає байта послідовності можуть збігатися. Це означає, наприклад, що при пошуку символу D (код 44) можна помилково знайти його входять до другої частини послідовності з двох байтів символу «Д» (код 84 44). Щоб з'ясувати, яка послідовність є правильною, програма повинна врахувати попередні байти.
Ситуація ускладниться, якщо ведучий і замикає байт співпадуть. Це означає, що для зняття неоднозначності буде проводитися зворотний пошук до досягнення початку тексту або однозначної послідовності коду. Це не тільки неефективно, але не захищене від можливих помилок, адже досить одного неправильного байта, щоб весь текст став нечитабельним.
Формат перетворення Юнікоду дозволяє уникнути даної проблеми, тому що значення ведучої, замикає і одиночної одиниці зберігання інформації не збігаються. Завдяки цьому всі кодування Юнікоду підходять для пошуку і порівняння, ніколи не даючи помилкового результату через збіг різних частин коду символів. Той факт, що дані форми кодування дотримуються принцип ненакладення, відрізняє їх від інших мультибайтних східно кодувань.
Іншим аспектом неперетинання є те, що кожен символ має чітко визначені межі. При цьому відпадає необхідність в скануванні невизначеного числа попередніх символів. Дану особливість кодувань іноді називають самосинхронізацією. Спотворення однієї одиниці коду введе до спотворення тільки одного символу, а навколишні символи залишаються недоторканими. У 8-бітному форматі перетворення, якщо покажчик посилається на байт, що починається з 10xxxxxx (замість двійкового коду), для пошуку початку символу потрібно від одного до трьох зворотних переходів.
узгодженість
Консорціум Юнікоду в повній мірі підтримує всі 3 форми кодувань. Важливо не протиставляти UTF-8 і Юнікод, адже всі формати перетворення - однаково правомірні втілення форм кодування символів стандарту Юнікод.
Байт-орієнтація
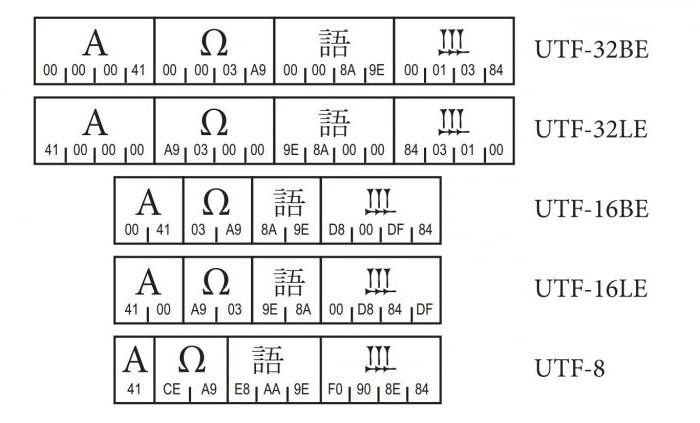
Для подання символу UTF-32 знадобиться одна 32-бітна одиниця коду, яка збігається з кодом Юникода. UTF-16 - від однієї до двох 16-бітних одиниць. А UTF-8 використовує до 4 байт.
Кодування UTF-8 створена для сумісності з байт-орієнтованими системами на основі ASCII. Велика частина існуючого програмного забезпечення та практика інформаційних технологій тривалий час спиралися на уявлення символів у вигляді послідовності байтів. Безліч протоколів залежить від незмінності і використовує або уникає спеціальні керуючі символи. Простим способом адаптувати Юнікод до таких ситуацій можна, застосувавши 8-бітове кодування для представлення символів Юнікоду, еквівалентних будь-якому символу ASCII або керуючому символу. Для цього і призначена кодування UTF-8.
Мінлива довжина
UTF-8 - кодування змінної довжини, що складається з 8-бітних одиниць зберігання інформації, старші біти яких позначають, до якої частини послідовності належить кожен окремий байт. Один діапазон значень відведений для першого елемента послідовності коду, інший - для наступних. Це забезпечує не перетинання кодування.
ASCII
UTF-8-кодування повністю підтримує коди ASCII (0x00-0x7F). Це означає, що символи Юнікоду U + 0000-U + 007F конвертуються в єдиний байт 0x00-0x7F UTF-8 і таким чином стають не відрізнятись від ASCII. Більш того, щоб уникнути багатозначності, значення 0x00-0x7F не використовуються більше ні в одному байті представлення символів Юнікоду. Для кодування неідеографіческіх символів, відмінних від ASCII, використовується послідовність з двох байтів. Символи діапазону U + 0800-U + FFFF представлені трьома байтами, а додаткові з кодами більше U + FFFF вимагають чотирьох байтів.
Область застосування
Кодуванні UTF-8 зазвичай віддається перевага в протоколі HTML і йому подібним.
XML став першим стандартом з повною підтримкою кодування UTF-8. Організації, що займаються стандартизацією, теж її рекомендують. Проблема підтримки в адресах URL, відмінних від ASCII-символів, була вирішена, коли консорціум W3С і інженерна група IETF дійшли згоди про кодування всіх виключно в UTF-8.
Сумісність з ASCII полегшує перехід до нового програмного забезпечення. З UTF-8 працює більшість текстових редакторів, в тому числі JEdit, Emacs, BBEdit, Eclipse і "Блокнот" операційної системи Windows. Жодна інша форма кодування Юнікоду не може похвалитися такою підтримкою з боку інструментальних засобів.
Перевага кодування полягає в тому, що вона складається з послідовності байтів. З рядками UTF-8 легко працювати в C та іншими мовами програмування. Це єдина форма кодування, що не вимагає мітки порядку байтів BOM або оголошення кодування в XML.

самосинхронізація
В оточенні, що використовує 8-бітну обробку символів, в порівнянні з іншими багатобайтові кодуваннями, UTF-8 має наступні переваги:
- Перший байт послідовності коду містить інформацію про його довжині. Це підвищує ефективність прямого пошуку.
- Спрощено процедуру знаходження початку символу, так як початковий байт обмежений фіксованим діапазоном значень.
- Відсутня перетин значень байтів.
порівняння переваг
UTF-8-кодування компактна. Але при застосуванні для кодування східно символів (китайських, японських, корейських, що використовують знаки китайського письма) використовуються 3-байтниє послідовності. Також UTF-8-кодування поступається іншим формам кодування по швидкості обробки. А двоичная сортування рядків дає той же результат, що і двоичная сортування Юникода.
Схема кодування символів
Схема кодування символів складається з форми кодування символів і способу побайтного розташування одиниць коду. Для визначення схеми кодування стандартом Юникода передбачено використання початкової мітки порядку байтів (BOM, Byte order mark).
При включенні BOM в UTF-8 функція мітки обмежується тільки зазначенням на використання форми кодування. Проблеми визначення порядку байтів у UTF-8 немає, так як її розмір одиниці кодування дорівнює одному байту. Використання BOM для даної форми кодування не є ні обов'язковим, ні рекомендованим. BOM може зустрічатися в текстах, конвертованих з інших кодувань, що використовують мітку порядку байтів, або для сигнатури кодування UTF-8. Являє собою послідовність з 3 байтів EF 16 BB 16 BF 16.
Як задати кодування UTF-8
В UTF-8 встановлюється за допомогою наступного коду:
˂meta http-equiv = "Content-Type" content = "text / html; charset = utf-8" ˃
У PHP кодування UTF-8 задається за допомогою функції header () на самому початку файлу після завдання значення рівня виведення помилок:
error_reporting (-1);
Charset = utf-8 ");
Для підключення до баз даних MySQL кодування UTF-8 встановлюється так:
mysql_set_charset ( "utf8");
В CSS-файлах кодування символів UTF-8 вказується так:
@charset "utf-8";
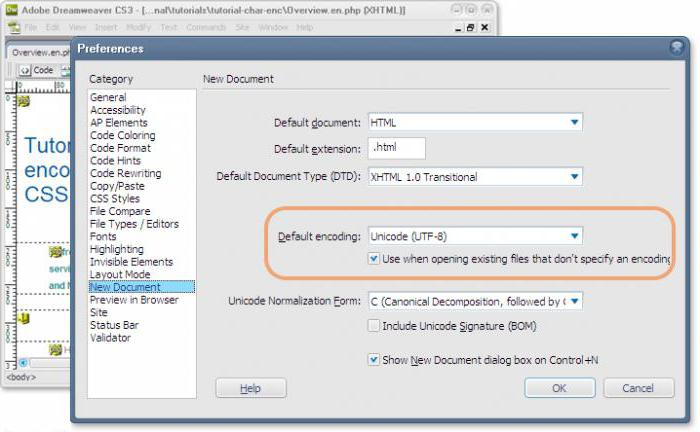
При збереженні файлів всіх типів вибирається кодування UTF-8 без BOM, інакше сайт працювати не буде. Для цього в програмі DreamWeave потрібно вибрати пункт меню «Модифікації - Властивості сторінки - Тема / Кодування», змінити кодування на UTF-8. Потім слід перезавантажити сторінку, прибрати галочку з пункту «Підключити Юнікод сигнатури (BOM)» і застосувати зміни. Якщо який-небудь текст на сторінці або в базі даних був введений іншою формою кодування, то його потрібно ввести нові або перекодувати. При роботі з регулярними виразами обов'язково використовувати модифікатор u.
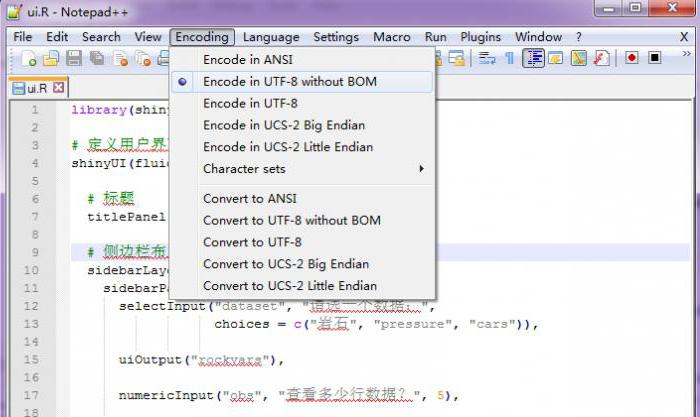
В текстовому редакторі Notepad ++, якщо кодування відмінна від UTF-8, через пункт меню «Перетворити в UTF-8 без BOM» змінити кодування і зберегти в кодуванні UTF-8.
альтернативи немає
В умовах глобалізації, коли політичні і мовні кордони стираються, набори символів, які мають місцеві особливості, стають малопридатними. Юнікод є єдиним набором символів з підтримкою всіх локалізацій. А UTF-8 - приклад правильної реалізації Юникода, яка:
- підтримує широкий діапазон інструментальних засобів, в тому числі сумісність з кодуванням ASCII;
- має стійкість до спотворення даних;
- проста і ефективна при обробці;
- не залежить від платформи.
З появою UTF-8 дискусії про те, яка форма кодування або набір символів краще, стали безглузді.